Teaching Robots Flexibility Through Demonstrations
Robots have become an essential part of modern manufacturing, particularly for assembly tasks. However, they often face a key limitation: they execute tasks in fixed sequences. Imagine a robot waiting idly because it can’t begin its next task without the right tool, even though other tasks are ready to be completed. What if we could make robots smarter, enabling them to adapt to different situations, like humans do when they change their approach based on available resources? That’s where our research comes in. We’ve developed a method that allows robots to learn flexible task strategies directly from expert demonstrations, opening new doors for how robots execute long, complex tasks. For more details please check out the full paper.
Learning Sub-goals and Task Structure from Demonstrations
To overcome the limitations of rigid robots, we’ve designed a method that learns sub-goals and their temporal order directly from human demonstrations. We use a probabilistic deterministic finite automaton (PDFA) to model the structure of a task and capture the preferences of the human demonstrators. Here’s how it works:
-
Sub-goals: We consider tasks that consists of multiple smaller steps (or sub-goals) that need to be completed. In a first step, we deploy clustering techniques to identify sub-goals from the demonstrations.
-
PDFA: Once we know the sub-goals, we construct a PDFA. This is a model that captures the temporal relationships between the sub-goals. The PDFA doesn’t just capture one way to complete the task but reflects all the variations shown by human demonstrators. The PDFA also assigns probabilities to different sequences of actions reflecting the preferences of the human demonstrators.
How Robots Can Use the PDFA
Once the PDFA is learned, it can be used to generate task plans for the robot. Each sub-goal in the task is assigned a probability, representing how likely or preferred it is based on the expert demonstrations. The robot can then choose the most preferred path to complete the task. But what makes this approach really useful is its flexibility if something goes wrong, like a material being unavailable, the robot can quickly adapt and re-plan its actions. Instead of getting stuck, it picks an alternative route, ensuring the task keeps moving forward even in unexpected situations.
Stacking Blocks
Consider the task of building two stacks of colored blocks where each block should be placed in a specific position.
Capture Demonstrations
In this example, the human demonstrator illustrates all six possible sub-goal orderings. Since there are a total of nine demonstrations, certain sub-goal sequences are repeated more frequently than others.

Learn Sub-Goals and Task Structure
By analyzing the probabilities, it becomes clear that the preferred block placement sequence is: green, yellow, red, and blue.
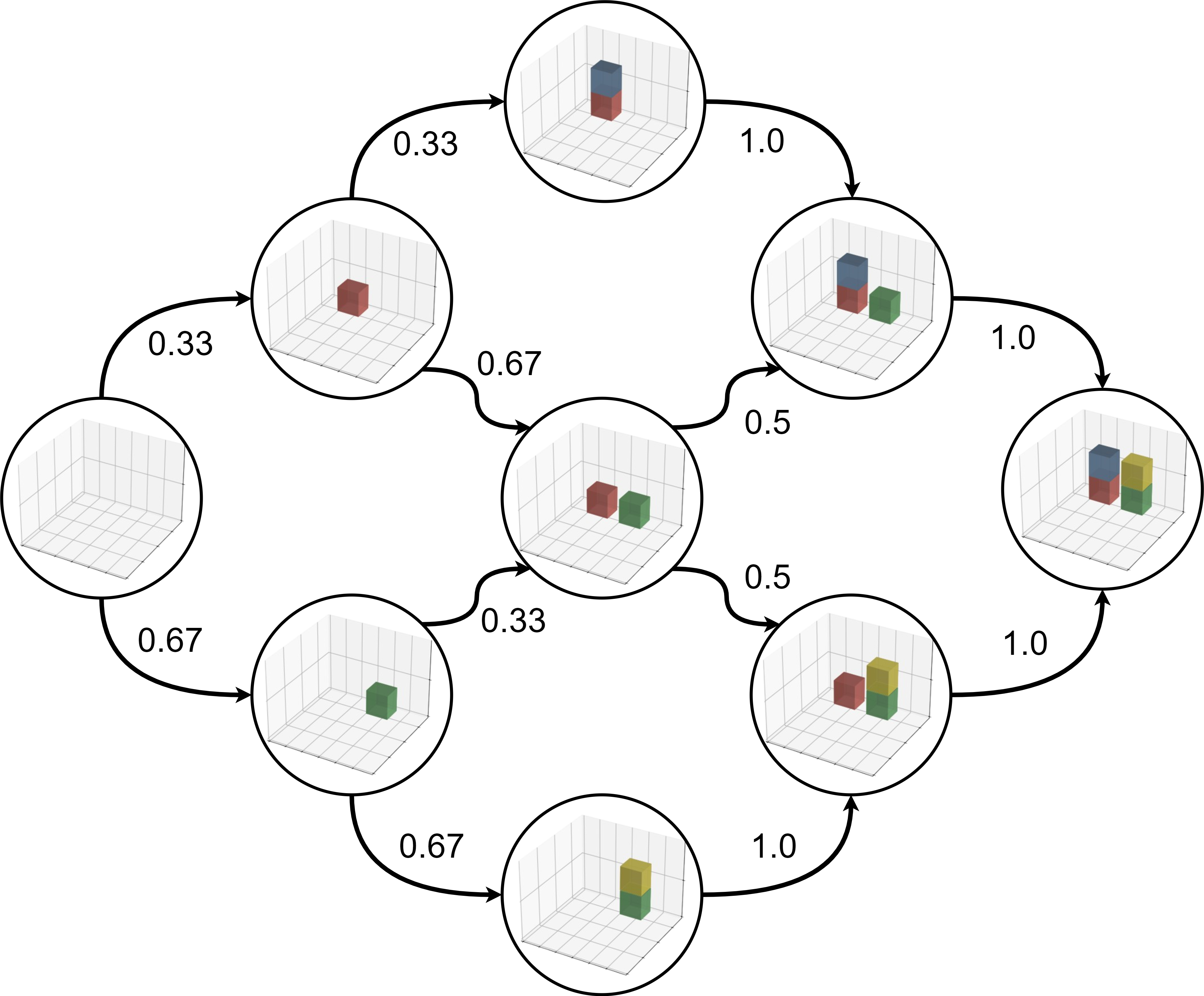
Deploy
In the video below, the preferred plan is updated twice because the next sub-goal is unreachable, specifically because the yellow block is not yet available.
Advantages Over Traditional Methods
Our approach offers several key advantages:
- Interpretability: The PDFA provides a clear, interpretable task model that domain experts can easily modify.
- Flexibility: The PDFA enables robots to adapt their behavior to changing conditions, like missing parts or tools, instead of idling.
- Scalability: By focusing on sub-goals, we improve the efficiency and scalability of learning task specifications compared to traditional methods.
Limitations
- Low-level control: we assume a low-level controller is available for completing the sub-goals.
- Assumption of clear sub-goals: The method assumes that sub-goals can be clearly identified from the demonstrations. In more complex, unstructured tasks, or when sub-goals are not as easily discernible, clustering and sub-goal extraction may be challenging, potentially leading to inaccuracies in the inferred PDFA.
What’s Next?
Moving forward, we plan to enhance our approach by incorporating reinforcement learning such that an optimal policy can be learned autonomously for each sub-goal. This approach will eliminate the need for a predefined low-level controller, allowing our method to handle tasks with more complex sub-goals where such controllers may not always be available. Additionally, we aim to explore automatic feature selection techniques to refine sub-goal clustering, minimizing the reliance on domain expertise to define meaningful feature spaces and making the system more versatile and scalable.