Thesis topics
Below you can find an alphabetically sorted list of DECIDE's thesis topics for 2026-2027.
Table of contents
- Accelerating Vision Transformers with Multiplier-Free Inference: Bit-Serial APoT Quantization on Edge GPUs
- Accurate Temporal Tracking of Crops and Weeds to Automate Labelling in Precision Agriculture
- Adaptive camera control for drone detection
- Adaptive Feedback for Human–Agent Collaboration in Minecraft
- Adaptive VLM Guidance for Collaborative Autonomous Vehicle Duckiebots
- Agentic AI for Automated LCI Generation from Food Product Descriptions
- Agentic Control for Single Arm to Multi-Arm Robotic Manipulation
- Automated Grow Point Detection for Precision Laser weeding
- Automatic Disassembly of LEGO Structures
- Collaborative Robotics via Limited Expert Data and Solo Simulation
- Combinatorial Optimization in Logistics
- Cooperative Transport with Explicit Communication
- Creating capable but not unbeatable competitors in a VR sailing game
- Data and resource-Efficient Dynamics Models for indomain learning
- Decentralized Control Algorithms for Robot Control
- Fusing Fourier Neural Operators and State Space Models for Global Context in Computer Vision
- Fusion Sensor Data for Occlusion Aware Path Planning in Robotic Manipulation
- Language-Grounded World Modeling and World-Grounded Language Reasoning for Robotics
- Layered Hyperdimensional Computing for Efficient Anomaly Detection
- Learning Natural-Looking NPC Avatar Animation in Unity with Reinforcement Learning and Human Videos
- Mitigating the Impact of Dynamic Visual Distractors on Vision-Based Robotic Navigation
- Quantization aware training combining Backpropagation and Predictive Coding
- Real-Time Guidance of Pre-Trained Models at Deployment Time for Human Motion Generation
- Retrieval Augmented Generation Chatbot for Farmer LCA advice
- Self-Supervised Foundation Models for Hyperspectral Imaging
- Trajectory Planning for Robot Tomato Harvesting
Accelerating Vision Transformers with Multiplier-Free Inference: Bit-Serial APoT Quantization on Edge GPUs
Problem statement
While Vision Transformers (ViTs) demonstrate exceptional representational capacity across computer vision tasks, their deployment on resource-constrained edge platforms faces severe system-level bottlenecks. Chief among these is the Memory Wall: during inference, the repeated transfer of large weight tensors from off-chip DRAM to on-chip compute units frequently saturates available memory bandwidth. Consequently, execution stalls on memory latency, leaving processing units heavily underutilized.
Current efficiency optimization methods such as INT8 quantization, structured pruning, and knowledge distillation exhibit significant limitations. They often rely on vendor-specific hardware, alter the model’s inductive biases, or require extensive task-specific retraining. As a result, the viability of a hardware-agnostic, architecture-preserving approach that simultaneously relieves memory bandwidth pressure and bypasses the need for dedicated multiplier units remains largely unexplored.
Additive Powers-of-Two (APoT) quantization offers a theoretically rigorous solution to this gap. By representing weights as finite sums of signed power-of-two terms, APoT replaces standard multiply-accumulate (MAC) operations with hardware-efficient binary bit-shifts and additions. Coupled with a bit-serial execution scheme, APoT substantially reduces both the memory footprint and the arithmetic complexity of inference. However, its transferability to ViTs remains an open question. Unlike the Convolutional Neural Networks (CNNs) on which APoT has typically been evaluated, ViTs exhibit pronounced inter-channel magnitude variations and outlier activation patterns characteristic of self-attention. How these distributional shifts impact quantization fidelity, kernel efficiency, and the accuracy-efficiency benchmarks on real edge hardware is not yet established.
Thesis goal
This thesis investigates the feasibility and operational limits of multiplier-free ViT inference using bit-serial APoT quantization on edge GPUs. The central objective is to empirically characterize the conditions under which this approach yields tangible improvements in memory efficiency and inference throughput, while identifying the architectural and hardware constraints that govern its efficacy.
The research pursues three interconnected lines of inquiry:
-
Distributional Transferability: Assessing whether APoT quantization requires structural adaptation to accommodate the unique weight and activation distributions of attention-based architectures.
-
Kernel Viability: Evaluating whether custom bit-serial CUDA kernels on edge GPUs successfully translate APoT’s reduced memory bandwidth requirements into measurable latency improvements, or if shift-accumulate serialization overhead negates these gains.
-
Arithmetic Intensity Analysis: Determining if memory bandwidth is the definitive constraint for ViT linear layers on edge targets, and whether APoT bit-serial execution effectively shifts the arithmetic intensity of these operations.
Grounded in hardware performance profiling and model analysis under realistic edge power constraints, this work treats the accuracy-efficiency tradeoff across various APoT bit-width configurations as a primary object of study. This thesis aims to delineate the practical scope of multiplier-free inference for transformer-based vision models establishing which architectural components are amenable to APoT quantisation, identifying strict computational bottlenecks, and defining the resulting deployment tradeoffs for high-accuracy vision systems operating under smaller power budgets.
Accurate Temporal Tracking of Crops and Weeds to Automate Labelling in Precision Agriculture
Problem statement
To improve the sustainability of agriculture and reduce its environmental impact, precision agriculture relies on targeted weed management, ranging from site‑specific herbicide spraying to weed lasering and the activation of mechanical hoeing elements. These systems make extensive use of computer vision and supervised AI, with different models deployed for different crops and applications. It is crucial that these machines operate accurately and do not damage the crops. To ensure reliable performance under a wide variety of conditions—including differing soil types—the models are regularly retrained. However, this continuous development cycle of supervised AI is expensive due to the large amounts of labelled data required. As a result, these precision machines often come with high annual subscription costs for access to the AI models, on top of their already substantial purchase price. Further automation of the labelling process could significantly reduce these costs. At ILVO, we develop prototypes of agricultural robots and their software systems (Willekens et al., 2025b). During field operations, the GNSS position of the camera’s Field of View (FoV) on the implement can be determined, enabling the localization of both crops and weeds (Willekens et al., 2025a). This is a promising strategy. The ability to identify individual crop plants and weeds throughout the growing season makes it possible to: a) evaluate the effectiveness of the applied weed control technique; b) automatically assign labels at known crop or weed locations; c) monitor the growth of individual crop plants (Willekens et al., 2025c).

Thesis goal
In this thesis, you will improve the accuracy of this process. You will investigate how pixel‑level matching can be used to track plants over time with sub‑millimeter precision, enabling the applications described above. Throughout the project, you will also have the opportunity to validate your research on one of ILVO’s robotic platforms.
References:
- Willekens, A., Callens, B., wyffels, F., Pieters, J., & Cool, S. R. (2025a). Cauliflower centre detection and 3-dimensional tracking for robotic intrarow weeding. PRECISION AGRICULTURE, 26(2). https://doi.org/10.1007/s11119-025-10227-3
- Willekens, A., Temmerman, S., wyffels, F., Pieters, J., & Cool, S. (2025b). Development of an agricultural robot taskmap operation framework. JOURNAL OF FIELD ROBOTICS, 42(8), 4256–4287. https://doi.org/10.1002/rob.70003
- Willekens, A., wyffels, F., Pieters, J., & Cool, S. (2025c). Integrating plant growth monitoring in a precision intrarow hoeing tool through canopy cover segmentation. NEURAL COMPUTING & APPLICATIONS, 37(24), 20139–20160. https://doi.org/10.1007/s00521-025-11445-6
Adaptive camera control for drone detection
Problem statement
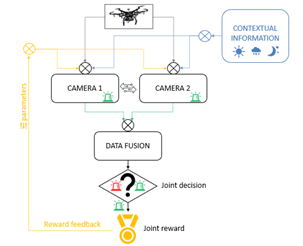
Drone detection is an active research domain within the protection of critical infrastructure. In a fully operational setting, a multisensor configuration is typically deployed in which different technologies (e.g. radar, RF detection and optical sensors) are used in a complementary manner to achieve robust and reliable detection. Within this broader framework, optical sensors play an important role in visual identification and verification.
However, performance is highly dependent on environmental factors such as light intensity, weather conditions, background complexity and reflections. In addition, camera settings (exposure, gain, frame rate, zoom, focus) have a direct impact on the detectability of aerial objects. Statically configured sensors often result in suboptimal detection when environmental conditions change. Adaptive sensor control, where parameters such as exposure, gain, frame rate, zoom and focus are dynamically adjusted, has the potential to enable more robust and faster detection.
In this thesis, a mobile and scalable test setup is provided consisting of two optical cameras (at least one pan-tilt-zoom). The camera parameters can be actively controlled via a Raspberry Pi. The setup is deliberately kept compact to allow flexible experimentation in different environments. A small drone, such as the DJI Mini 2, is used as the experimental detection target. The thesis focuses on adaptive sensor control and AI-based detection as building blocks for later integration into a broader multisensor platform.
Thesis goal
At the start of the thesis, a mobile acquisition system is already available. It consists of two optical cameras (at least one pan-tilt-zoom), controlled via a Raspberry Pi responsible for reading and adjusting sensor and camera parameters. The student will use the system operationally, analyze it, and further optimize it in line with the research objectives.
A small drone is provided for test flights. Without additional training, flights up to 10 meters altitude are permitted. At the start of the project, VITO will provide an initiation and training day on site (Geel), during which both the drone system and the acquisition setup will be explained and tested. Additionally, the student may complete the free European Open Category A1/A3 training and online exam, allowing flights up to 120 meters altitude (in permitted locations).
The student will subsequently conduct independent drone flights under varying conditions (lighting, background, distance, altitude) and develop a structured experimental test protocol. A dataset will be constructed in which image data, applied sensor settings and relevant environmental conditions are systematically logged.
Based on this dataset, the student will develop an AI-based model for drone detection. This may involve classical deep-learning approaches or a reinforcement learning (RL) strategy in which detection and/or sensor adaptation are optimized. In parallel, the student will design an adaptive control strategy that dynamically adjusts camera parameters based on environmental conditions or detection quality. The added value of this adaptive approach will be experimentally compared with static configurations. The figure shows a conceptual example of the described setup.Finally, the student will analyze the limitations of the above setup and formulate recommendations for future integration within a broader multisensor detection concept.
Practical Requirements and Supervision
This thesis is organized by VITO. As one of Europe’s leading sustainability research centres, VITO, with 1,300 employees, turns scientific insights into groundbreaking technological innovations, AI solutions, and policy advice. We do this with a single objective: to help the world thrive for at least 1,000 more years.
VITO is the leading science-to-technology partner for companies, governments, and society in their sustainability transition. We have concentrated our research activities on three key areas where we aim to make the greatest impact in Flanders, Europe, and globally: a regenerative economy, a healthy living environment, and resilient ecosystems.
Supervision will take place primarily online, with bi-weekly progress meetings to discuss results, challenges, and next steps. On-site meetings, our research groups being based in Mol and Genk, will be limited but will be required at the beginning of the thesis for hardware familiarization, system setup, and experimental planning. They may also be needed later in case of hardware-related issues, system adjustments, or specific experimental needs. The student is expected to work independently, plan experimental campaigns proactively, and ensure clear documentation of both software and experimental results throughout the thesis.
This master thesis can only be chosen with explicit approval from VITO. Such approval will be granted based on an online interview with the student prior to registering in Plato for the project.
Adaptive Feedback for Human–Agent Collaboration in Minecraft
Problem statement
Working together with an AI agent in a game often sounds more fun than it actually is. Even when the agent is on your team, the collaboration can still feel awkward: it may do its own thing, fail to notice when you are stuck, or give help that is too generic or too late to matter. In a game like Minecraft, where players have to gather resources, craft items, plan ahead, and divide work, this quickly becomes frustrating. There are many ways for teamwork to break down: a teammate can focus on the wrong subtask, forget an important prerequisite, waste resources, repeat mistakes, or simply not know what to do next. A useful collaborative agent should therefore do more than just complete the task itself. It should also notice when its teammate is struggling and provide feedback that is relevant to the current situation.
This thesis explores how to make such collaboration feel more natural by giving the agent a better understanding of its teammate. Instead of only reacting to the game state, the agent can track signals such as task progress, completed subtasks, likely intentions, repeated mistakes, or weaker parts of the teammate’s behavior. Based on this information, it can decide when feedback is needed and what kind of feedback is most useful at that moment.

Thesis goal
The goal of this thesis is to design and evaluate a collaborative agent that can provide adaptive feedback during cooperative Minecraft tasks, first with a deliberately weak or imperfect AI teammate and, as a possible extension, later with human users. Rather than only focusing on completing the task, the agent should help its teammate in a way that is better matched to the current situation.
Two directions are possible:
-
Feedback based on progress and skill tracking
- Track the teammate’s progress in the task, such as completed subtasks, missing prerequisites, bottlenecks, or weak points in execution.
- Use this information to generate targeted feedback that helps the teammate continue more effectively.
-
Teammate modeling for feedback simulation
- Build a model of the teammate that captures how it behaves during the task and how it reacts to feedback.
- Use this model to simulate different feedback strategies and study which types of intervention are most effective.
Adaptive VLM Guidance for Collaborative Autonomous Vehicle Duckiebots
Problem statement
LLMs and vision-language models are increasingly used to guide robot behavior by providing high-level feedback, reward signals, or coordination advice. This is appealing because it offers a more flexible alternative to manually designing all guidance rules by hand. The problem is that this guidance is often treated as fixed, even though what helps the agents can change over time.
In this thesis we use Duckietown as a testbed. Duckietown is a small-scale autonomous driving environment in which miniature self-driving cars, called Duckiebots, navigate a model city with roads, intersections, traffic signs, and other vehicles. While the environment itself is controlled, it allows us to create different scenarios such as changing layouts, traffic situations, or simulation-to-real transfers. In such cases, guidance that was useful before may no longer fit the situation and can become less effective.
This thesis explores how to close the loop between the guiding model and the Duckiebots. Instead of only using the VLM to guide the agents, the system should also use the observed outcomes of the Duckiebots to improve future guidance, allowing the model to adapt to the agents and changing scenarios.
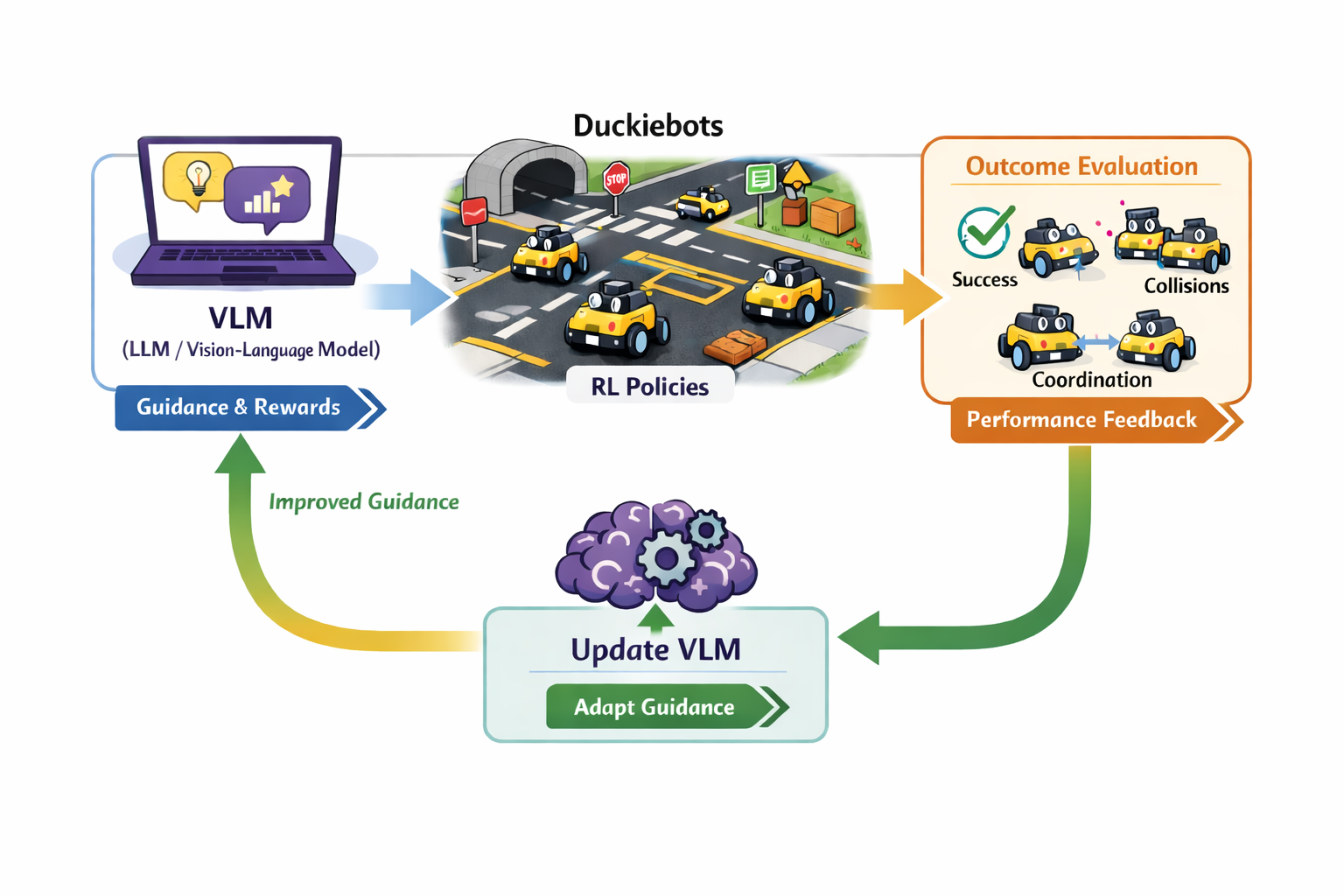
Thesis goal
The goal of this thesis is to design and evaluate a closed-loop system in which a vision-language model provides guidance for collaborative Duckiebots, while the observed behavior and performance of the Duckiebots are used to improve the quality of future guidance. The work builds on an existing Duckietown setup in which such guidance is already used for collaboration, and extends it toward a setting where the model can adapt when the scenario changes. The final result should be a framework that can be evaluated in terms of task performance, collaboration quality, and the ability of the guidance to remain effective across changing conditions.
Agentic AI for Automated LCI Generation from Food Product Descriptions
Problem statement
Life Cycle Assessment (LCA) is a systematic, standardised methodology for quantifying the environmental impacts of a product, process, or service across its entire life cycle, from raw material extraction through production, distribution, use, and end-of-life disposal. This cradle-to-grave perspective is what distinguishes LCA from narrower environmental analyses, which might focus only on a single stage such as manufacturing or transport. A crucial part of LCA is Life Cycle Inventory in which all material and energy inputs and outputs (including emissions) are compiled for every process within the system boundary. Constructing a life cycle inventory (LCI) for a food product requires an expert to manually identify all involved processes -including upstream processes-, locate matching entries in LCA databases (such as ecoinvent), and assemble them into a coherent model — a process that can take days for a single product. For food companies without in-house LCA expertise, this is a major barrier to environmental self-assessment.

Thesis goal
The goal of this thesis is to automate this process by designing an agentic AI that accepts a product name or ingredient list as input, autonomously searches the web for process and supply chain information, and uses an LLM to map retrieved information onto LCA database entries — assembling a draft LCI with uncertainty flags where information is ambiguous or missing. The system would function as a first-pass LCA scaffold rather than a finished assessment, with expert review required before results are used for reporting. The core research questions concern retrieval accuracy, hallucination risk in process-to-database matching, and how to communicate output uncertainty clearly.
Agentic Control for Single Arm to Multi-Arm Robotic Manipulation
Problem statement
Vision-language models (VLMs) are capable of interpreting images. Therefore, these models could be employed to give instructions. For example, given an image of three cubes, you can prompt a VLM to provide instructions on building a tower — “place the red cube at the bottom, put the green cube on top off it, and end with the blue cube”. While easily interpreted by humans, there still exists a gap between these high-level instructions and primitives for robotic manipulation.
Thesis goal
In this thesis, you will develop a practical framework, that bridges low-level robot control and high-level guidance.
Starting (possibly in simulation) with one robot arm, you will explore what is required to succesfully execute a given task (e.g. “pick up the red cube”). Contrary to vision-language-action (VLA) models, that are fine-tuned for the task of robotic manipulation, and operate in a closed loop system (new images are fed continuously), you will investigate the feasibilty of off-the-shelf VLMs. Initial questions for this step are:
- Which forms of low level control are present?
- How are these controls combined in actions?
- What information do VLMs require, be it textual or images, to suggest actions?
- How frequent should this information be provided?
- How is feedback handled?

As an example, this step is deemed completed when the robot in the figure above can succesfully fetch the red cube off the conveyor belt.
In the next step, you will extend the single arm setup to a multi-arm setup. In this setup, two robot arms must cooperate to complete a task. Ideally, by joining forces, the robots complete this task in a more optimal manner as compared to a single arm. Some paths to explore:
- How are subtasks delegated?
- Can both arms operate independently, but cooperate through communication?
References
-
Kim et al., “OpenVLA: An Open-Source Vision-Language-Action Model”, 2024.
-
Gaboardi dos Santos et al., “ALRM: Agentic LLM for Robotic Manipulation”, 2026.
Automated Grow Point Detection for Precision Laser weeding
Problem statement
To enhance the sustainability of agriculture and reduce its environmental impact, precision agriculture increasingly relies on targeted weed management. Approaches range from site‑specific herbicide spraying to weed lasering and the activation of mechanical hoeing elements. In recent years, weed lasering has gained significant attention due to the strong potential of laser technology. In this method, weeds are thermally destroyed using an optimal energy dose. Unlike many alternative techniques, laser treatment has minimal interaction with the soil, preserving soil life and preventing buried weed seeds from being brought to the surface, where they could germinate. Thermal destruction is most effective at a very early weed growth stage; otherwise, substantially higher energy doses are required. This poses a considerable technical challenge. The growth points of these very small weeds must first be precisely located, after which the laser beam must be accurately aimed. Stereo cameras are often used to enable detection and 3D localization through computer vision. For this, the weeds must be identified in both the left and right images and correctly matched so that their 3D positions can be reconstructed using camera calibration. Despite the different viewpoints of the stereo pair, the detection model must mark the growth point consistently in both images; otherwise, the resulting 3D localization will be inaccurate.

Thesis goal
This thesis will investigate early and late fusion strategies for incorporating stereo images within a model architecture for growth‑point detection. The output of the detection algorithm will consist of pairs of pixel coordinates for each weed in the overlapping region of the stereo images. These coordinate pairs can then be combined with stereo calibration parameters to perform 3D reconstruction. This thesis is embedded in ILVO’s research on adaptive weed management. At ILVO, we develop prototypes of agricultural robots and their corresponding software systems (Willekens et al., 2025). This will enable you to validate your research in real‑world operational conditions.
References: Willekens, A., Temmerman, S., wyffels, F., Pieters, J., & Cool, S. (2025b). Development of an agricultural robot taskmap operation framework. JOURNAL OF FIELD ROBOTICS, 42(8), 4256–4287. https://doi.org/10.1002/rob.70003
Automatic Disassembly of LEGO Structures
Problem statement
For many products, the “right” disassembly procedure is not available as a clean robot program. Instead, it is scattered across web videos, repair guides, forum posts, or assembly manuals, often written for humans and assuming tool skill, context, and common sense. A robot that is handed an unfamiliar object therefore faces two linked challenges: it must first infer a plausible step-by-step procedure from noisy online information (often effectively reversing an assembly plan), and then execute that procedure safely in the real world where perception is imperfect and contacts are unpredictable.
The difficulty is that web instructions rarely specify the details that matter for manipulation, such as the exact grasp points, which fasteners are actually accessible, how much force/torque is safe, or what to do when a step fails because a part is stuck. Disassembly also has strong “one-way” constraints: removing the wrong part early can block access, create a drop hazard, or damage components. Even if a high-level sequence is correct, execution requires continuous re-evaluation of state (is the screw removed, did the cover release, is the part still constrained) and adaptation when reality deviates from the reference instructions.
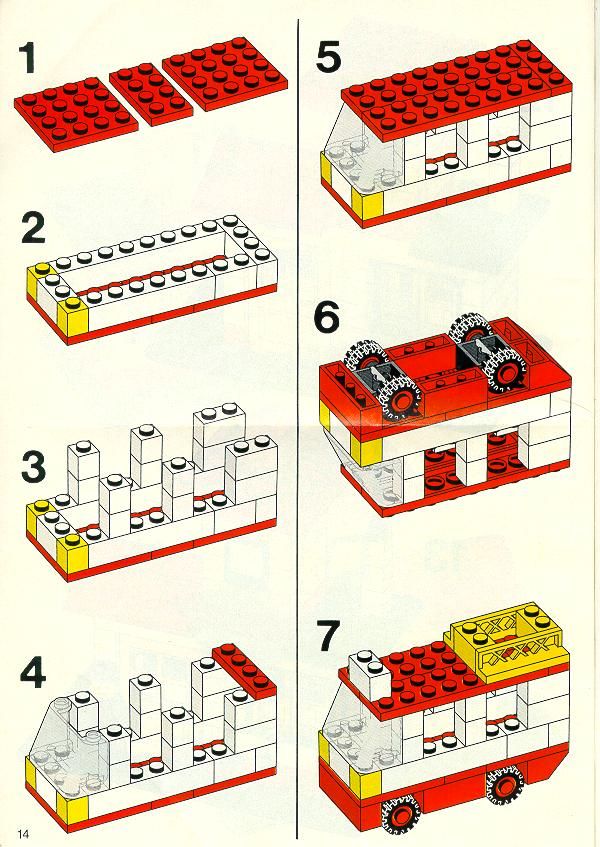

Thesis goal
Develop and evaluate (simulation-first) a robotic disassembly pipeline for a Franka Emika Panda in which the robot is given an object and uses online videos/instructions to infer an appropriate disassembly sequence, then executes it in simulation with robust perception and contact-aware manipulation. The thesis will focus on how to turn unstructured web guidance into a grounded sequence of robot-relevant steps and preconditions, and how to couple that sequence to motion and interaction control so the robot can verify progress, detect failure (e.g., stuck parts), and recover by revising the plan rather than blindly continuing. Primary evaluation will be in simulation to allow controlled experiments over object variants, incomplete/contradictory instructions, and execution disturbances, with the end goal of defining a clear pathway to later sim-to-real transfer.
Collaborative Robotics via Limited Expert Data and Solo Simulation
Problem statement
Creating interactive human-robot systems has become a major focus in recent research. In our work, we are particularly interested in the human–humanoid interaction setting, closely connected to an ongoing project in our research group aimed at developing an interactive robotic pianist.
Specifically, consider the task of training a humanoid robot to perform a piano duet with a human musician. For this setting, we have already collected expert human–human duet recordings, as illustrated in the figure on the right. In contrast, we also have access to a simulation environment that allows unlimited solo piano practice, shown on the left. While this simulation enables the robot to acquire strong individual playing skills, expert data for collaborative duet performance is limited and expensive to obtain.

The central research challenge is therefore: how can we combine the duet coordination skills and interaction (cooperation) learned from the limited expert duet demonstrations with the solo performance abilities acquired through large-scale simulation?
You are encouraged to explore this question within the context of the robotic pianist project, or to apply the same research idea to other domains that involve similar challenges of combining solo learning in simulation with scarce collaborative demonstrations (e.g., the Overcooked environment).
Thesis goal
First of all, this thesis does not require robotics expertise and is therefore approachable by any student with an interest in machine learning and an Informatics / Computer Science background.
Among other aspects, this thesis includes:
- Defining a more concrete research topic in collaboration with your promotor.
- Identifying and selecting an appropriate dataset to develop and evaluate your methodology.
- Exploring methods to learn from multiple data sources and combine control policies (e.g., through skill composition, offline-to-online learning, or other related techniques).
- Developing skills that are highly valued in industry, such as real-world deployment, sim-to-real learning, and joint training with both simulated and real-world data.
More generally speaking, we expect you to:
-
Formulate Research Questions: Develop targeted research questions to identify and address the unsolved problem(s) within the described problem setting based on the latest related literature.
-
Strive For Novelty: Design original methods, preferably going beyond state-of-the-art research, to provide elegant and robust solutions to the identified problems.
-
Bridge Research and Application: As a minimum requirement, you must adapt and integrate SOTA techniques into a specific downstream application (such as the interactive pianist). This will demonstrate your ability to translate the latest theoretical advancements into functional, real-world implementations.
Combinatorial Optimization in Logistics
Optioryx is a Ghent-based software company that builds the AI layer on top of existing warehouse management systems. Our two products, Pulse and Flux, are deployed at logistics providers in more than 25 countries. Pulse focuses on warehouse process optimization for picking, packing, and slotting. Flux supports mobile data capture and dimensioning. Every day, our algorithms process thousands of real-world orders under tight latency constraints, optimizing 3D packing arrangements, pallet stacking plans, order batches, and SKU-to-location assignments.
Problem statement
This master thesis will focus on one of several core combinatorial optimization problems in our platform. Together with the supervisors, the student will refine this into a concrete and well-scoped research question, with room for either practical algorithmic engineering or a more theoretical or experimental comparison of methods.
Possible problem domains include:
- Cartonisation: given a set of items with dimensions, weight, and stacking constraints, pack them into one or more boxes such that an objective such as cost, fill rate, or number of containers is optimized.
- Palletisation: given heterogeneous boxes, construct stable and space-efficient pallets while respecting constraints such as weight-on-top, dividers, and interlocking.
- Order batching: given warehouse pick orders with known locations, group them into batches that minimize total travel distance under capacity constraints.
- Warehouse slotting: assign SKUs to storage locations to minimize expected picking distance under weight, dimension, and compliance constraints.
Thesis goal
Possible research directions include:
- designing faster algorithms or subroutines using advanced data structures or pruning strategies
- improving existing heuristics to achieve better solution quality within similar runtime
- developing hybrid, exact, or metaheuristic methods for selected variants
- constructing stronger benchmark or oracle methods to assess current production algorithms
The goal is not only to implement a working solution, but also to investigate and justify algorithmic choices through principled experimentation and comparison with relevant baselines.
What we offer
The student will have access to a large collection of anonymized, real-world production instances. Proposed methods can be evaluated on runtime, solution quality, robustness, and where possible, the gap to optimal or best-known solutions. You will work closely with our engineering team and receive hands-on guidance throughout the project. In addition, you will collaborate with PhDs in Computer Science Engineering and Kaggle Masters, offering a strong mix of academic depth and practical machine learning and optimization expertise. Results that prove competitive may be integrated into our production systems. The thesis can be oriented towards practical algorithmic engineering or towards a more theoretical and experimental comparison of solution methods. We are happy to adapt the exact focus to the student’s interests.
Who we are looking for
We are looking for a motivated master student in Computer Science Engineering with strong programming skills, ideally in Python and preferably also C or C++, and a strong interest in combinatorial optimization, operations research, algorithms, or learning-based optimization. A good fit for this thesis is someone who enjoys solving hard algorithmic problems, is comfortable with experimental evaluation, and is interested in building methods that can have direct impact in real-world logistics systems
Cooperative Transport with Explicit Communication
Problem statement
Collaborative transport is difficult because the robots are tightly coupled through the object, but each robot only has a partial and different view of what is going on. A robot mainly perceives what is in front of it and what it feels at its own contact point, while crucial events can happen elsewhere on the object. When a large object moves through clutter, small local issues—one corner catching on an edge, a wheel slipping, a contact point losing friction, a brief jam—can immediately change the object’s motion for everyone. The result is that robots can unintentionally work against each other: one keeps pushing while another is trying to pivot, forces build up, the object rotates unexpectedly, and recovery becomes hard because the team must change behavior quickly without losing stable contact.
Leader–follower control reduces the complexity because one robot chooses the motion and others comply, but it often fails in exactly these moments. Followers typically only observe delayed motion commands or indirect cues from object motion and force, which makes it hard to know why the leader is slowing, turning, or stopping. Under occlusions, contact-mode changes, and communication limits, followers may keep applying force at the wrong time, worsening slip or jamming. This motivates an explicit communication layer that exchanges short, grounded statements about what each robot locally observes and intends to do, rather than streaming raw state, which is consistent with general findings on how coordination improves when partners share task-relevant information (Vesper et al., 2017) and with cooperative transport work emphasizing the role of coupling, partial observability, and communication constraints (Tuci et al., 2018; An et al., 2023). Recent learning-based cooperative transport studies further motivate evaluating such communication under realistic disturbances (Bernard-Tiong et al., 2024; Pandit et al., 2025).
Picture from https://github.com/some45bucks/IsaacLab-HARL.
Thesis goal
Develop and evaluate, primarily in simulation using NVIDIA Isaac Sim / Isaac Lab, a hybrid leader–follower cooperative transport framework in which low-level stability is handled by conventional motion/force controllers, while an LLM/VLM-based module produces and interprets physically grounded, low-bandwidth messages about local observations and intended actions. The thesis will study how to train and integrate this module—such as imitation from a centralized “teacher” policy versus RL-style adaptation versus hybrids—and will benchmark when explicit messaging improves robustness over baselines like no communication, raw-state broadcast, or fixed leader–follower rules. Evaluation will focus on settings where transport typically breaks down: occlusions, sensing noise, contact-mode changes, and constrained or unreliable communication.
References:
- An, X. et al. (2023). Multi-Robot Systems and Cooperative Object Transport: Communications, Platforms, and Challenges. IEEE Open Journal of the Computer Society, 4, 23–36. https://doi.org/10.1109/OJCS.2023.10023955
- Bernard-Tiong, I.-S. et al. (2024). Cooperative Grasping and Transportation using Multi-agent Reinforcement Learning with Ternary Force Representation. arXiv. https://doi.org/10.48550/arXiv.2411.13942
- Pandit, B. et al. (2025). Multi-Quadruped Cooperative Object Transport: Learning Decentralized Pinch-Lift-Move. arXiv. https://doi.org/10.48550/arXiv.2509.14342
- Tuci, E. et al. (2018). Cooperative object transport in multi-robot systems: A review of the state-of-the-art. Frontiers in Robotics and AI, 5, 59. https://doi.org/10.3389/frobt.2018.00059
- Vesper, C. et al. (2017). Joint action: mental representations, shared information and general mechanisms for coordinating with others. Frontiers in Psychology, 7, 2039. https://doi.org/10.3389/fpsyg.2016.02039
Creating capable but not unbeatable competitors in a VR sailing game
Problem statement

Spatial Sail is a high-fidelity virtual reality sailing simulator developed specifically for the Meta Quest and Horizon VR ecosystems. Built within the Unity game engine, it leverages realistic physics to simulate the complex interactions between wind, water, and vessel. Its primary purpose is to provide a training ground for sailors to practice tactical maneuvers in a risk-free digital environment.
Currently, the opponents in a race are driven by elementary, hand-coded rules. This leads to rather predictable paths. The goal of the thesis is to animate these non-playable characters using machine learning.To generate realistic behavior and avoid bots with superpowers, we should not learn the behavior from scratch but use imitation learning from human data.
This thesis will be conducted at the company DigitMedia, located in the Wintercircus. An interview with the company is required before selecting this topic.
Thesis goal
The key objective is to desing behavior algorithms for the NPC sailing bots so they are credible competitors in races against human players. This involves implementing a hybrid machine learning strategy combining reinforcement learning with imitation learning. You will collect and utilize the gameplay data of human sailors within the VR environment to teach the bots authentic maneuvers.
The simulator is built in Unity, and provides integration with Unity ML-Agents and the Sentis inference engine. The student wills have access to the complete C# source code, enabling low-level modifications to the boat’s handling and physics. Students can get access to a Meta Quest 3 VR headset if needed.
Data and resource-Efficient Dynamics Models for indomain learning
Problem statement
To understand and anticipate their environments, AI systems rely on “dynamics models”, i.e. internal simulations of how the world evolves over time. Unfortunately, current models often require massive amounts of training data to learn effectively and rely on complex probabilistic methods that suffer from training instability. When these models try to predict multiple steps into the future, their representations tend to “drift” or become uninformative, making them unreliable for long-horizon forecasting.
The problem we want to solve is creating a dynamics model that efficiently learns the underlying rules of a specific domain without being severely data-hungry, while remaining stable and physically plausible over long sequences.
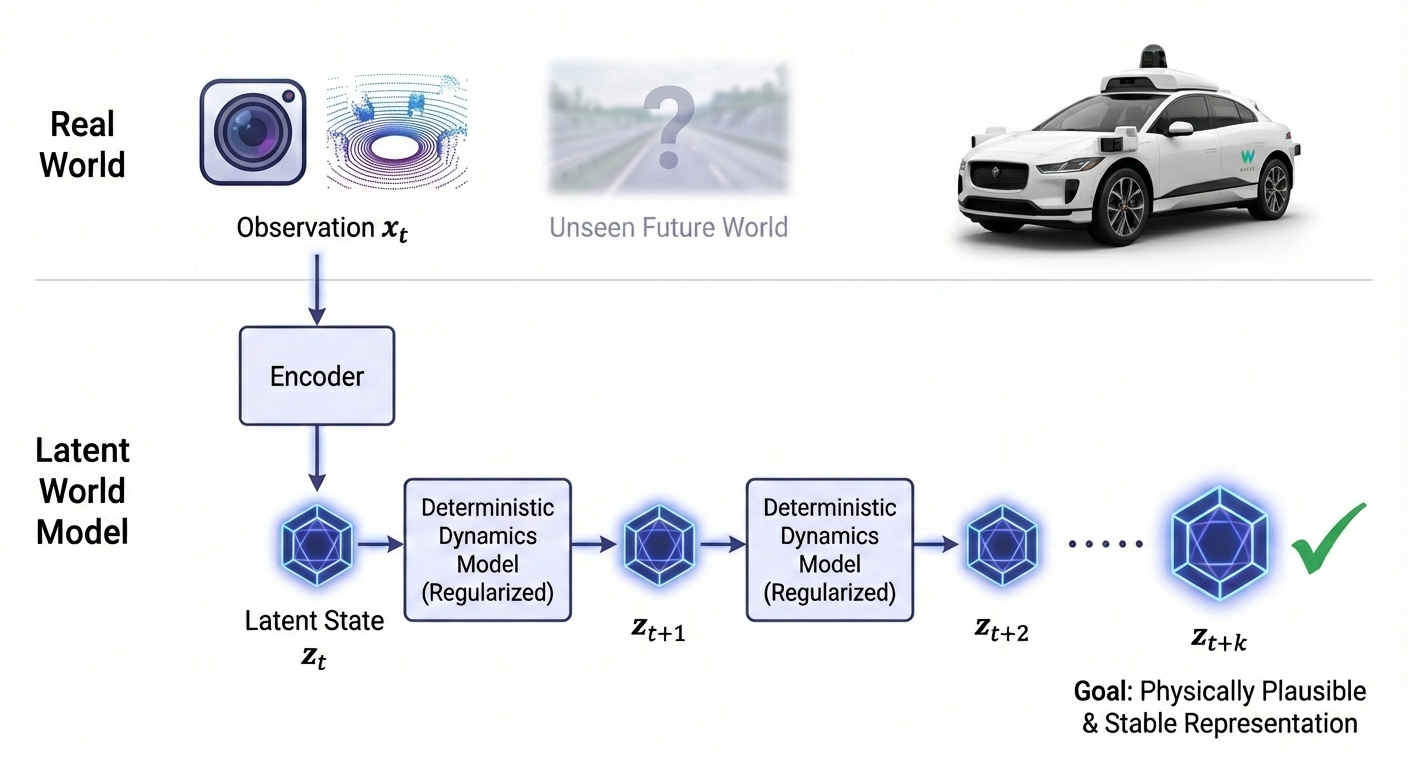
Thesis goal
This Master’s thesis aims to develop a stable, in-domain dynamics model using an accessible and data-efficient approach. Instead of traditional probabilistic losses (like VAEs) that often require huge datasets to converge, we will explore deterministic frameworks with strong, straightforward regularization techniques to keep the learned latent space well-behaved and prevent the model from drifting.
The student will start by applying modern self-supervised predictive architectures to learn temporal transitions directly from limited sequences of data. The core research task is to investigate how to properly regularize these learned representations so that step-by-step predictions remain consistent over time. By evaluating the geometry of the learned space and its ability to accurately forecast future states, the project will validate whether this simpler, regularized approach yields a reliable dynamics model that can learn effectively in environments where data is scarce.
Decentralized Control Algorithms for Robot Control
Problem statement
Modern robotic systems typically rely on a fully centralized control architecture, where a single computational unit processess all sensory input and issues every motor command. The control logic is increasingly a huge neural network such as a Vision-Language Model, which implements a large generalist policy that directly maps sensor information to action.
Biological systems, from insects to humans, do not work this way. Many decisions are handled closer to where sensing and acting actually happen, without involving the brain at all. This thesis investigates a hybrid architecture in which a VLM-based generalist policy acts as a central “brain” for semantic understanding and high-level goal specification, while a set of decentralized controllers handle behavior closer to the actuators. The motivation for doing so is more than just latency: a local controller can keep the system operational when the link to the central unit is degraded, and offloading somes tasks to lightweight processors can significantly reduce energy consumption.

Thesis goal
The thesis focuses on a mobile manipulator performing pick-and-place tasks, with control distributed across three learned components: a central for task-level reasoning and goal specification, a mid-level arm controller handling trajectory planning, and a low-level arm controller managing torque, impedance and contact.
Several research questions can be investigated. How should the central brain communicate a goal to the mid-level controller, and can that interface be learned rather than hand-designed? When and how does authority transfer from the mid-level to the low-level controller during a reach-and-grasp motion? And since the low-level controller operates under tight latency and power constraints, it is worth asking whether non-conventional approaches such as reservoir computing or probabilistic computing (p-bits) are better suited here than standard deep reinforcement learning.
All experiments will start in a physics-based simulator (IsaacLab or MuJoCo), with the possibility of moving to a physical setup later if the student is interested.
Fusing Fourier Neural Operators and State Space Models for Global Context in Computer Vision
Problem statement
The landscape of computer vision is currently shifting. While Vision Transformers have dominated recent years, their computational cost grows quadratically with image size. To solve this, State Space Models (SSMs) like Vision Mamba have emerged. They process images by scanning them as a sequence of pixels or patches, achieving highly efficient linear time complexity.
However, this spatial scanning approach introduces a new fundamental flaw: a weak inductive bias for global context. Because SSMs process pixels step-by-step, they struggle to immediately capture the “big picture” of an image. Furthermore, they are highly sensitive to image resolution; an SSM trained on small images often fails when tested on larger ones because the sequence length and spatial layout change drastically.
The frequency domain offers a natural solution to this problem. Fourier Neural Operators (FNOs) process data continuously by modeling global frequencies rather than discrete local pixels. This makes them inherently aware of global structure and completely independent of image resolution. Yet, training purely frequency-based models for standard vision tasks remains computationally heavy and unstable. The field currently lacks an architecture that successfully balances the local efficiency of SSMs with the global, resolution-invariant reasoning of FNOs.
Thesis goal
The primary objective of this thesis is to design, implement, and evaluate a hybrid vision architecture that integrates Fourier Neural Operators (FNOs) with State Space Models (SSMs). The core hypothesis is that processing visual data in the frequency domain provides a superior inductive bias for global structure, and that fusing this with spatial SSMs will yield a model that is both highly efficient and resolution-invariant.
This research will focus on architectural fusion strategies by investigating several open ended design questions. First, you will explore architectural design to determine how frequency and spatial data should interact. This includes evaluating routing strategies, such as using an FNO as a global token-processing “stem” prior to the SSM, or running them as parallel branches that fuse deep in the network. Second, you will empirically validate resolution invariance to test if the FNO-enhanced SSM can maintain high accuracy when trained on low-resolution images and evaluated on high-resolution images a task where standard spatial models typically degrade. Finally, you will analyze the efficiency trade-offs and the computational cost of integrating frequency transforms, specifically identifying how much frequency data (Fourier modes) can be truncated without losing the global structural benefits.
Fusion Sensor Data for Occlusion Aware Path Planning in Robotic Manipulation
Problem statement
The world has a certain predictability to it. If a human working in front of a laptop takes their coffee mug, and places it (out of sight) behind the laptop screen, they usually have little trouble fetching that mug again, even though it is not visible. In a similar matter, should that human place the coffee mug on a little platform on a conveyor belt, as is present in the image below, by seeing the platform with the mug move, they have no trouble placing their hand further down the line to fetch the mug again, even if at some point the mug is not visible. This predictability remains a challenge in robotic manipulation.
Thesis goal
In this thesis, you will explore how multiple (depth) camera sensors can be combined with neural networks to predict the path of objects moving on a conveyor belt, and how to make these predictions robust to occlusions. Given this path, it should be possible to control a robot arm to fetch these objects off the conveyor belt, even when they are not visible.
Language-Grounded World Modeling and World-Grounded Language Reasoning for Robotics
Problem statement
Robots need to predict the consequences of their actions before acting, especially in long-horizon or ambiguous tasks where a purely reactive policy is not enough. This is why world models are becoming important in robotics: they allow the robot to imagine possible future states and use those imagined futures for planning and control. In parallel, large language models are increasingly used in robotics for high-level planning, instruction following, uncertainty communication, and clarification, because they can represent goals, constraints, and alternative courses of action in a flexible and human-readable way. Recent work already points toward both directions of interaction: language can condition world-model rollouts, as shown for example in LUMOS, Dynalang, Ctrl-World, and Say, Dream, and Act (Nematollahi et al., 2025; Lin et al., 2023; Guo et al., 2025; Gu et al., 2026), and predicted futures can be interpreted or judged through language-oriented reasoning, as explored in FOREWARN and VLWM (Wu et al., 2025; Chen et al., 2025).
The remaining problem is that these two capabilities are still not tightly integrated in a single control loop. In most current approaches, language is either only an input that specifies a task, or only a layer on top of a planner, while the world model remains an internal prediction module whose imagined futures are not directly exposed for language-based reasoning. As a result, the robot may be able to predict futures without being able to explain or question them, or it may be able to produce language-level plans without grounding them in predicted physical outcomes. For robotic control in realistic settings, this is a serious limitation: when the robot is uncertain, when multiple futures are plausible, or when the task is underspecified, it should be able not only to imagine outcomes, but also to communicate those expectations, identify uncertainty, and ask for clarification. The core problem is therefore how to connect world-model imagination and language reasoning in both directions, so that each improves the other during planning and execution.
Thesis goal
The goal of this thesis is to develop a bidirectional LLM–world-model framework for language-guided tabletop manipulation. Given a high-level natural-language instruction, the robot should use the LLM to extract subgoals, constraints, and ambiguities, and use the world model to imagine possible futures for different action sequences. The predicted futures should then be translated into a representation that the LLM can reason over, so it can compare alternatives, explain expected outcomes, identify uncertainty, and, when needed, ask a clarification question before execution. The system will be evaluated on multi-step pick-and-place and rearrangement tasks with ambiguous instructions, obstacle-induced replanning, and recoverable execution failures. The central question is whether this two-way coupling between language reasoning and physical imagination improves task success, robustness, and interpretability compared with one-way language-conditioned planning baselines.
References:
-
Chen, D., et al. (2025). Planning with Reasoning using Vision Language World Model (VLWM).
-
Gu, S., et al. (2026). Say, Dream, and Act: Learning Video World Models for Instruction-Driven Robot Manipulation.
-
Guo, Y., et al. (2025). Ctrl-World: A Controllable Generative World Model for Robot Manipulation.
-
Lin, J., et al. (2023). Learning to Model the World with Language.
-
Nematollahi, I., et al. (2025). LUMOS: Language-Conditioned Imitation Learning with World Models.
-
Wu, Y., et al. (2025). FOREWARN: VLM-In-the-Loop Policy Steering via Latent Alignment.
Layered Hyperdimensional Computing for Efficient Anomaly Detection
Problem statement
Deep learning models have become the standard for anomaly detection in complex datasets, such as industrial sensor streams, healthcare monitoring or satellite telemetry data. However, these models often require significant computational resources and extensive training time, making them difficult to deploy on resource-constrained edge devices. Furthermore, traditional anomaly detection techniques often rely on classification-based approaches that require labeled examples of normal and abnormal behavior, which are frequently unavailable in real-world scenarios.
Hyperdimensional Computing (HDC) offers a promising, hardware-efficient alternative by representing data using high-dimensional vectors and performing light-weight algebraic operations. While HDC has shown great success in classification tasks with the encoding, training and inference pipeline, its application to anomaly detection is underdeveloped. Current HDC methods struggle to capture complex, multi-scale temporal or spatial dependencies, which is necessary to identify subtle anomalies. A “layered” or hierarchical HDC approach could potentially bridge this gap, allowing for robust learning where the HDC model recognizes normal patterns without explicit anomaly labels.
Thesis goal
The goal of this thesis is to develop and evaluate a layered HDC framework specifically designed for unsupervised anomaly detection. The research aims to leverage the efficiency of HDC for complex pattern recognition in real-time environments.
Several strategies could include:
- Multiple associative memories based on different levels of bundling and binding.
- Hybrid HDC-Neural models: investigate neural feature extractors to project data into the Hyperdimensional space.
- Encoding: explore how local feature hypervectors can be bound and bundled across different temporal or spatial scales.
Learning Natural-Looking NPC Avatar Animation in Unity with Reinforcement Learning and Human Videos
Problem statement
NPC avatar animation in games often looks unnatural, even when the character is doing the right thing. An NPC may reach the correct location, turn at the right moment, or interact with an object successfully, yet its motion can still feel stiff, robotic, or unrealistic. This quickly breaks immersion, especially in interactive environments where characters need to adapt their behavior on the fly instead of replaying a fixed animation.
Traditional animation pipelines can produce high-quality results, but they usually require substantial manual work and do not scale easily to settings where characters must react flexibly to new situations. At the same time, collecting the kind of high-quality motion data needed for realistic animation is difficult and expensive in practice. This makes it interesting to look at more scalable alternatives. In this thesis, videos of humans are used as a source of natural behavior, from which a reward or scoring signal can be learned that captures how natural a movement looks. That learned signal can then be combined with reinforcement learning, so that an NPC not only learns to solve a task, but also learns to move in a more human-like way while doing so.
Thesis goal
The goal of this thesis is to investigate how reinforcement learning and human video data can be combined to improve NPC avatar animation in Unity. More specifically, the thesis studies how to learn a naturalness reward from videos of human behavior and use that reward during reinforcement learning, so that an NPC is encouraged to complete its task while avoiding robotic motion. The work will focus on a Unity environment with an existing avatar and a limited set of tasks such as locomotion or object interaction. The final result should be an NPC controller that balances task success with motion quality, and that can be evaluated both on how well it performs the task and on how natural the resulting animation appears.
Mitigating the Impact of Dynamic Visual Distractors on Vision-Based Robotic Navigation
Problem statement
Modern Vision-Language-Action (VLA) models show promise for robotic control by mapping raw visual observations and natural language directly to continuous motor commands. However, these monolithic architectures often encounter difficulties when transitioning from simulations to the physical world. A primary cause is their sensitivity to dynamic aleatoric noise, such as moving shadows, flickering fluorescent lights, and sensor artifacts. Because these networks process spatial geometry and visual distractors through a single entangled latent space, the underlying Vision-Language Models struggle to separate uninformative background changes from actual physical obstacles.
Recent evaluations support this observation. Fei et al. (2025) note that changes across various perturbation dimensions, including lighting, background textures, and camera viewpoints, can lead to a substantial decrease in task success rates. This suggests an over-reliance on fixed visual features rather than a robust geometric understanding of the environment.
Guo et al. (2025) further highlight that VLAs are sensitive to a range of multi-modal perturbations across observations, actions, and environmental uncertainties. In these scenarios, the continuous action generation process is often the most affected. When exposed to out-of-distribution visual inputs, policies may maintain high-level task understanding but struggle with precise motor execution.
Additionally, physical hardware limitations compound these issues. Orjuela et al. (2026) demonstrate that VLA models experience measurable performance degradation when subjected to common sensor-level artifacts such as electronic noise, dead pixels, and lens contaminants. This indicates that geometric generalization is insufficient when the raw visual signal is degraded before interpretation. Ultimately, the difficulty in handling everyday visual distractors and sensor noise leads to unpredictable navigational errors during physical deployment.
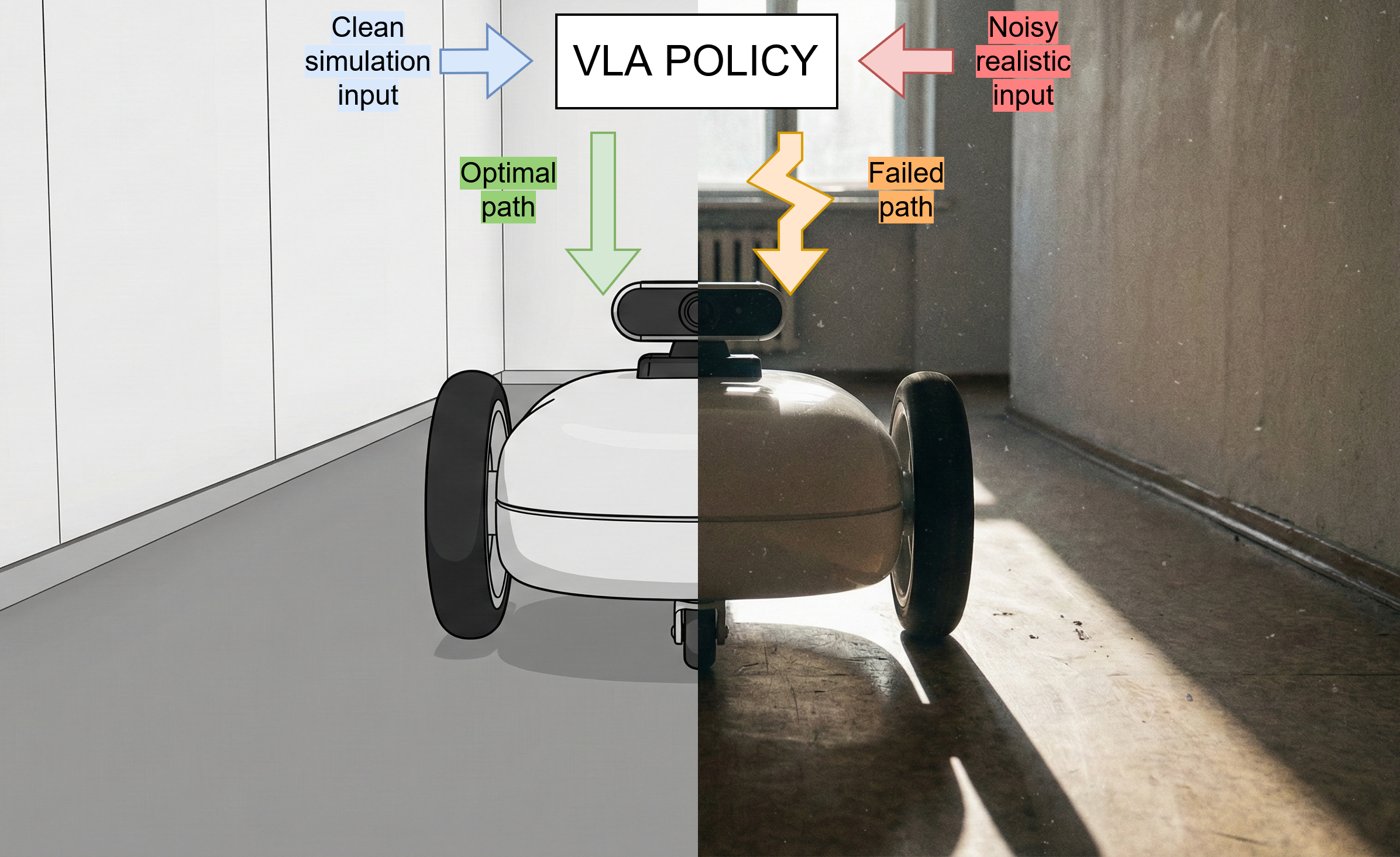
Thesis goal
The objective of this thesis is to address this vulnerability by developing a methodology that makes VLA policies robust against irrelevant visual noise. First, you will build a custom test environment within NVIDIA Isaac Sim to establish a simulated baseline with procedurally generated visual distractors. Next, you will research and implement a robust algorithmic solution to prevent the model from failing when exposed to these visual changes. Finally, you will perform a Sim2Real transfer by deploying the optimized policy to a physical differential drive robot to validate its navigation reliability against actual dynamic distractors in the real world.
References
Fei, Senyu, et al. “LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models.” arXiv preprint arXiv:2510.13626 (2025).
Guo, Jianing, et al. “On Robustness of Vision-Language-Action Model against Multi-Modal Perturbations.” arXiv preprint arXiv:2510.00037 (2025).
Orjuela, Daniel Yezid Guarnizo, et al. “Improving Robustness of Vision-Language-Action Models by Restoring Corrupted Visual Inputs.” arXiv preprint arXiv:2602.01158 (2026).
Quantization aware training combining Backpropagation and Predictive Coding
Problem statement
Quantization is applied to AI models to reduce their computational demand during inference, especially when running on edge devices.
Quantization both reduces the inference time, in particular for edge devices with specialized accelerators, and the required memory for storing the model weights.
Quantization techniques are divided into Post Training Quantization (PTQ) and Quantization aware Training (QAT).
While PTQ is the simplest quantization technique to implement, as it applies quantization after training, it usually comes with high accuracy drops.
On the other hand, QAT can provide a lower accuracy drop, simulating quantization during the model training.
Examples of QAT tools are TorchAO (Or et al. 2025) and qKeras (Coelho et al. 2021).
QAT, however, comes at the cost of higher computational demand during training and additional hyperparameter tuning complexity.
To address this computational overhead, alternative training techniques can be combined with Backpropagation to enhance quantization flexibility.
Predictive Coding is a training technique that relies only on local weight updates (van Zwol et al. 2024) and has been shown to be suitable for being combined with Backpropagation.
Thesis goal
The goal of this thesis is to investigate alternative QAT techniques implying Predictive Coding.
Instead of performing a quantization aware Backpropagation-based training from scratch, the training could begin with a classic floating-point Backpropagation-based training.
Predictive Coding-based training could be used, on the same data, as a quantization aware training tool in the last training phase.
It has been proven that the weights obtained from Backpropagation can be a suitable starting point for Predictive Coding-based training (Cardoni et al. 2025).
Relying on local updates, Predictive Coding could provide a more flexible approach than Backpropagation for layer-wise quantization of the starting weights.
In this thesis, you will design and implement Predictive Coding-based QAT techniques, using them on benchmark models.
You will also compare the accuracy and computational cost obtained with these techniques against State-of-the-Art QAT tools on the same models.
References
- Or, A., Jain, A., Vega-Myhre, D., Cai, J., Hernandez, C. D., Zheng, Z., … & Samardžić, A. (2025). TorchAO: PyTorch-Native Training-to-Serving Model Optimization. arXiv preprint arXiv:2507.16099.
- van Zwol, B., Jefferson, R., & van den Broek, E. L. (2024). Predictive coding networks and inference learning: Tutorial and survey. ACM Computing Surveys.
- Coelho Jr, C. N., Kuusela, A., Li, S., Zhuang, H., Ngadiuba, J., Aarrestad, T. K., … & Summers, S. (2021). Automatic heterogeneous quantization of deep neural networks for low-latency inference on the edge for particle detectors. Nature Machine Intelligence, 3(8), 675-686.
- Cardoni, M., & Leroux, S. (2025). Predictive Coding-based Deep Neural Network Fine-tuning for Computationally Efficient Domain Adaptation. arXiv preprint arXiv:2509.20269.
Real-Time Guidance of Pre-Trained Models at Deployment Time for Human Motion Generation
Problem statement
We are interested in scenarios where a specific data modality can serve as guidance for a pre-trained model at deployment time. For example, trajectory sketches could be used to steer an autonomous navigation model. In this setting, the guiding modality is not available during training, yet it should still influence the predictions (e.g., action selection) of the pre-trained model at inference time. While existing methods support this type of guidance, they often struggle to operate in real-time due to computational overhead.
To study this challenge, this thesis focuses on a concrete toy problem: goal-conditioned navigation with point- or trajectory-based guidance. Using environments such as OGBench or Minigrid, you will have the opportunity to construct a small dataset of expert guidance demonstrations, which could, for instance, be used to learn/ model the guidance dynamics.

Our longer-term goal is to move beyond this toy environment and apply similar techniques to more complex domains, such as human motion generation. If you are interested in tackling other challenges related to real-time human motion generation, we would also be happy to hear your ideas, even if they are still at an early stage.
This thesis topic sits at the intersection of generative modeling, reinforcement learning, machine learning, and computer graphics.
Thesis goal
The primary objective of this thesis is to enable real-time guidance by overcoming the computational bottlenecks of traditional sampling procedures used in existing approaches. To achieve this, you may explore several strategies, including:
- Policy distillation
- Constructing expert demonstration datasets
- Developing optimized inference techniques
Among other aspects, this thesis includes:
- Reviewing the literature on deployment-time pre-trained model guidance and identifying the factors that hinder real-time performance.
- Proposing your own methodology to address this problem, and implementing it to demonstrate real-time performance while ensuring reproducibility.
- Evaluating your approach against alternative methods using an appropriate evaluation methodology.
Retrieval Augmented Generation Chatbot for Farmer LCA advice
Problem statement
Life Cycle Assessment (LCA) is a systematic, standardised methodology for quantifying the environmental impacts of a product, process, or service across its entire life cycle, from raw material extraction through production, distribution, use, and end-of-life disposal. This cradle-to-grave perspective is what distinguishes LCA from narrower environmental analyses, which might focus only on a single stage such as manufacturing or transport. The Flanders Research Institute for Agriculture, Fisheries and Food (ILVO: instituut landbouw en visserijonderzoek) produces a continuous stream of LCA results, benchmarks, policy briefs, and research papers. This knowledge is largely inaccessible to the farmers it is meant to serve — not because it is hidden, but because navigating scientific and policy documents requires expertise most farmers don’t have. The result is a persistent gap between what research knows and what practice does.
Thesis goal
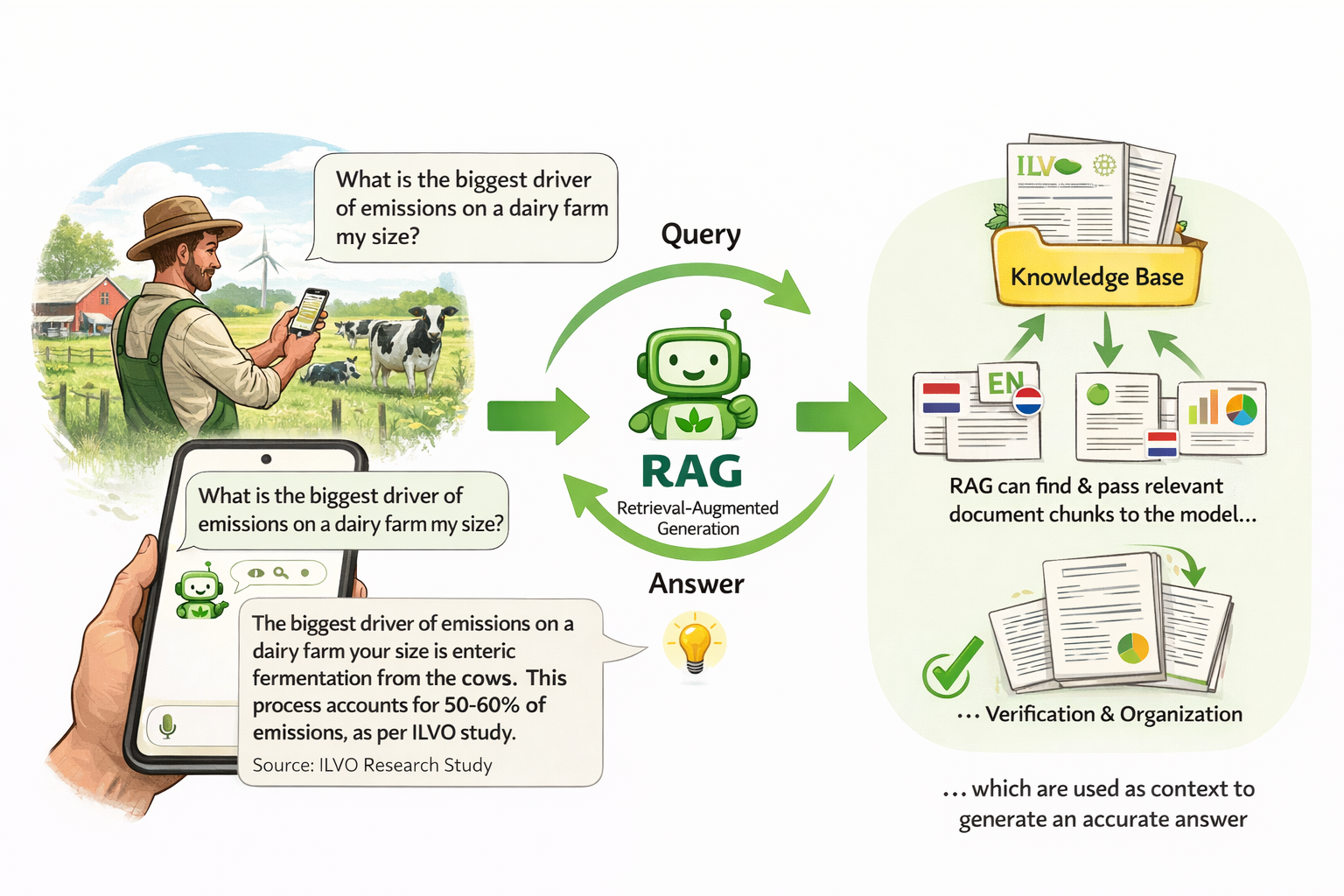
The goal of this thesis is make it easy for farmers to find relevant information by providing a Retrieval-Augmented Generation (RAG) chatbot that can answer questions, supported by a knowledge base of research results. Retrieval-Augmented Generation (RAG) is a technique that combines semantic search with language generation. Rather than expecting an LLM to memorize a knowledge base, RAG retrieves the most relevant document chunks at query time and passes them to the model as context for generating a response. Applied here, a farmer could ask “what is the biggest driver of emissions on a dairy farm my size?” and receive an answer grounded in ILVO’s actual research outputs, with source attribution. The key research challenge is how to standerize and organize the available data, how to handle the mix between Dutch and English inputs and how to verify the reponse.
Self-Supervised Foundation Models for Hyperspectral Imaging
Problem statement
Hyperspectral imaging captures detailed information tightly packed across many electromagnetic bands, making it highly valuable for fields like remote sensing, agriculture, and medical diagnostics. However, training deep learning models for these applications is severely hampered by a lack of labeled datasets. Furthermore, standard foundation models trained on regular RGB images (like normal photos) do not transfer well to the complex, high-dimensional nature of hyperspectral data.
How can we learn powerful and reusable representations of hyperspectral data without relying on massive amounts of manually labeled examples?
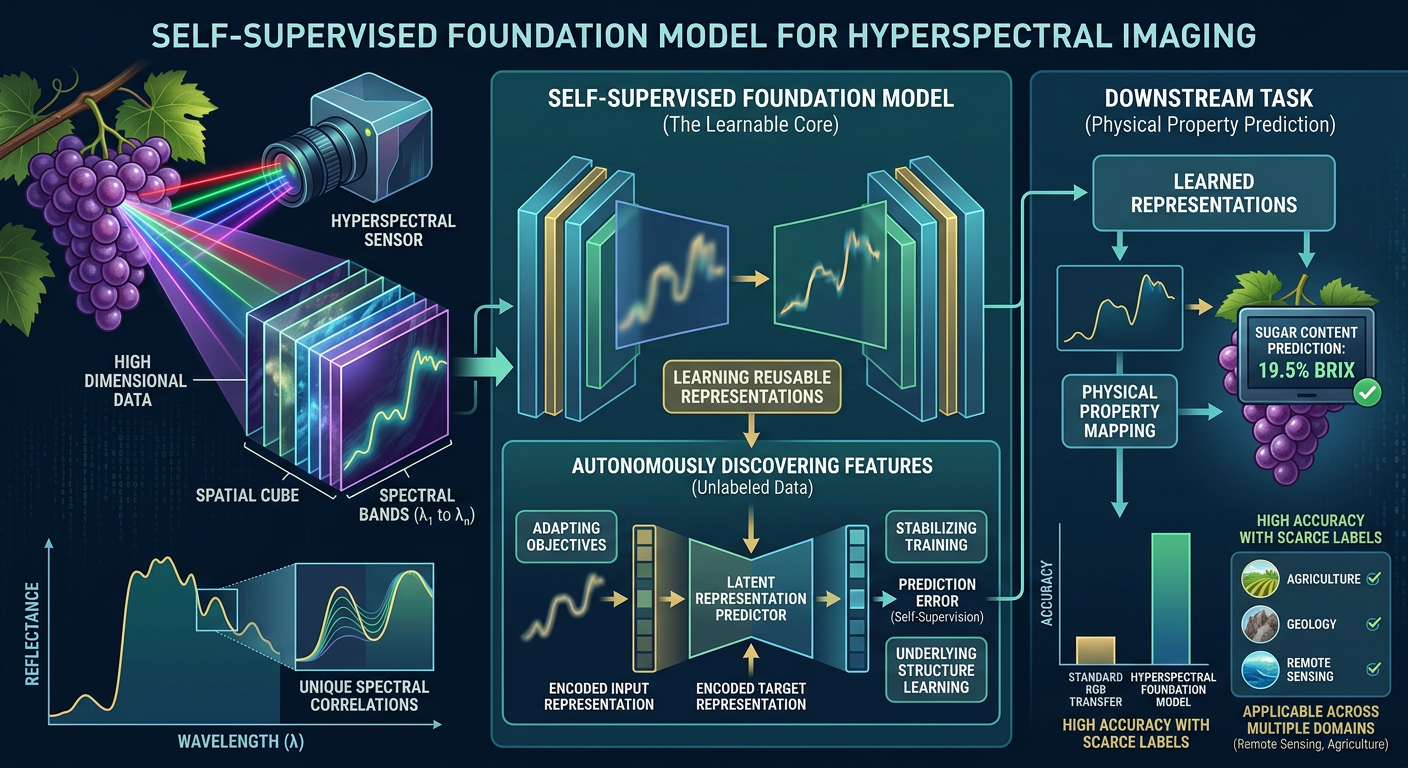
Thesis goal
This thesis focuses on developing a self-supervised foundation model specifically tailored for hyperspectral imaging. Instead of relying on manual labels, the model will learn the underlying structure of the data by solving predictive tasks (for example, applying modern predictive architectures to mask and predict parts of the signal).
Applying these techniques “out-of-the-box” is not trivial due to the unique spatial and spectral correlations present in the data. The student will investigate how to effectively adapt self-supervised learning objectives to handle this high dimensionality and stabilize the training process. The ultimate goal is to validate whether these autonomously discovered features can accurately capture physical material properties and significantly improve performance on downstream tasks where labeled data is scarce.
Trajectory Planning for Robot Tomato Harvesting
Problem statement
At the Robovision Agtech business unit, we are working on a myriad of computer vision AI projects. We provide the software that translates camera images into physical information of plants, such as their plant surface, the ideal cutting point in 3D for stem multiplication, their growth direction, etc.
Most of our projects are integrated with a robot that cuts or grabs a specific plant part. We have multiple machines that cut stems to multiply the plant in genetically identical clones. Most robots function in a controlled environment and on single plants. Although the plant itself is variable, most of the region in reach of the robot is empty, so in those cases the robot path can be easily computed with traditional methods such as potential-based methods and sampling-based methods combined with ad-hoc heuristics designed by an experienced engineer.

For our newest projects, such as the tomato harvester that works in a greenhouse, the traditional robot motion planning methods often fail to find an appropriate path due to the dense and variable scene.One by one, AI solutions are taking over domains at the edge of the state of the art. Current developments are focusing on physical AI with for example deep learning based path planning becoming increasingly potent. The most notable approach in this case is the use of reinforcement learning.
Thesis goal
In this master thesis, the goal is to control the robot directly via deep learning methods. To achieve this, Robovision provides their proprietary 3D robot path planning problem datasets for the tomato harvester. This dataset contains thousands of point clouds and related cutting points and should be of sufficient scale to achieve significant results.
The goals of this master thesis project are:
- literature review: investigate the state of the art in AI based trajectory planning
- focus on computational efficiency to achieve high throughput for the machines
- successfully train and infer a state of the art model on our datasets.
This master thesis is provided by Robovision, located in Ghent. To ensure proper guidance, students are expected to come at least weekly to the Robovision offices.