Navigating and Learning in an unknown environment
Imagine you’re exploring a building for the first time. As you move around, you create a mental map (or internal map/cognitive map) connecting the rooms, hallways, and doors based on what you see. Moreover, you can use your notion of space to determine how rooms are connected to each others without needing to open every doors. You expect a room behind a door, you can estimate that two doors on the same wall could lead to the same hallway.
Similarly, our model builds a map of its environment given what it perceives and infers. Our agent relies on what it sees but also uses predictions to estimate what might be in areas it hasn’t seen yet. Let’s dive into how this works in simple terms.
Learning and Expanding the Map
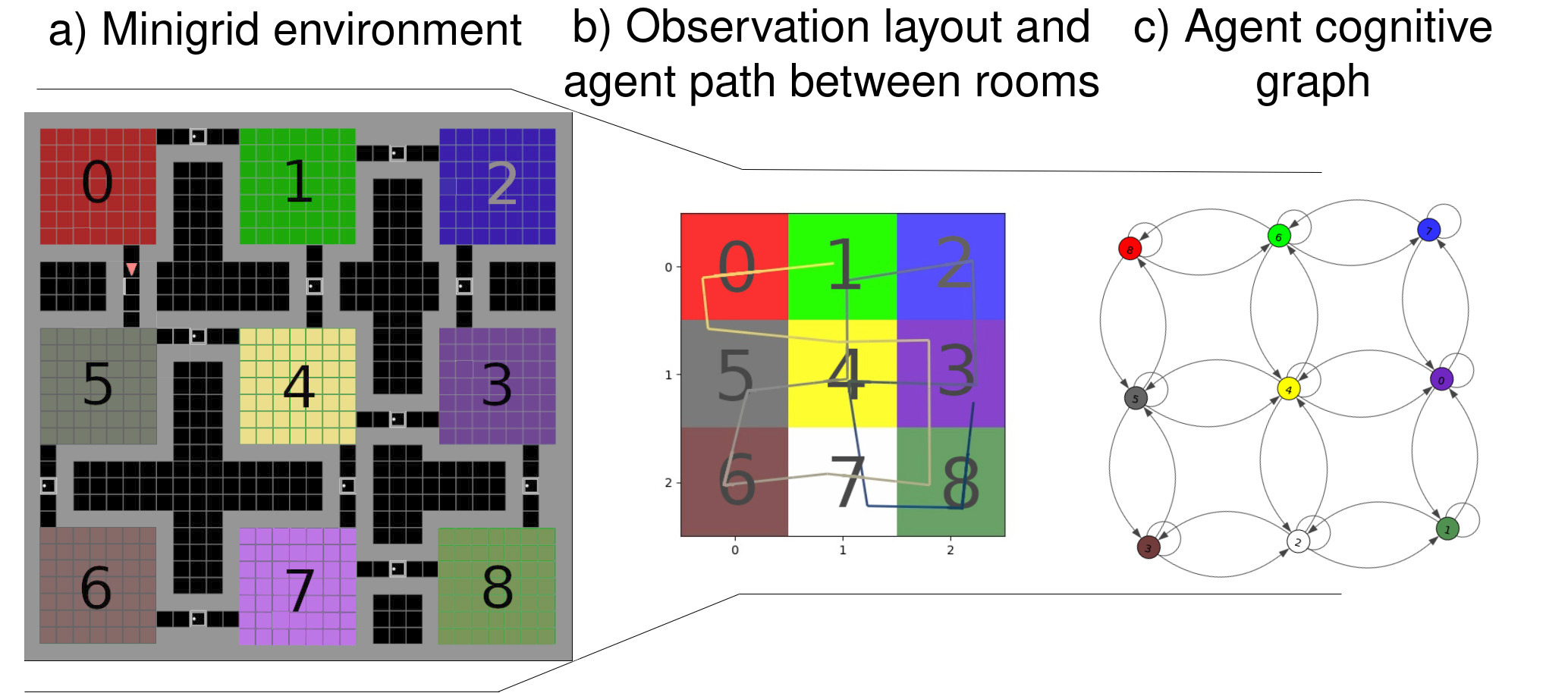
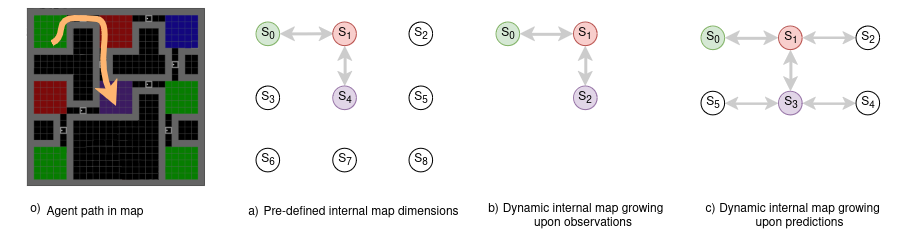
When the agent starts, it takes that location as its origin of reference during its exploration. As it moves, it uses visual observations and its belief about its position to estimate its current location. If something remarkably different from previous observations is observed given a Structural SIMilarity (SSIM) threshold, this new observation is memorised and incorporated with the current position to the current believed state. A state being a node in the internal map, represented as a topological graph to ease comprehension.

Once the agent is sure about its current whereabout (given a threshold of confidence) it makes predictions about possible motions considering its priors on what is an obstacle (walls) and what are not (doors). If the agent predicts a motion leading to an unexplored areas (unvisited location behind a door), it expands its internal map to include this new information: a state (node in graph) and pose lacking an associated observation. This makes the place really attractive while navigating using active inference and favouring exloration. We will come to that.
How Does the Agent Make Decisions?
The agent makes decisions based on the Active Inference framework and the balance between exploration and exploitation using active inference:
- Exploitation: What it prefers observing
- Exploration: How to maximise environmnet understanding
The agent uses something called Free Energy to make these decisions. Essentially, the agent tries to reduce its surprise by making accurate predictions. Surprise to be understood in the sense of Shanon Entropy. Our agent thus learns and adjusts its internal map to ensure that future surprises (like finding a door where it didn’t expect one) are minimised.
How Does the Agent Move and Explore?
When the agent moves, it doesn’t just wander aimlessly. It predicts possible outcomes in all directions (In a minigrid environement : left, right, forward, down and stay). It knows which directions are blocked by walls or doors thanks to priors on what doors and walls looks like, and it updates its map accordingly.
For instance, if the agent expects to find a new room when it moves to the right, but the door is closed, it will update its internal map to reflect that the path is blocked. Conversely, if a previous room has visually changed and the agent believes to know where it is, it will updates its beliefs about that room.
Why this solution?
Animals are remarkable at quickly learning and adapting to new environments, even when faced with surprises. Mimicking these natural abilities can greatly improve autonomous navigation. Our model is inspired by biological processes and offers several capabilities:
-
A Growing Map of the World: Our model creates a dynamic map of its environment, predicting possible paths and expanding its internal map based on imagined routes. This helps the agent adapt to new spaces quickly and navigate smoothly.
-
Flexible Learning in Unfamiliar Places: Unlike systems that need lots of training in specific environments, our model learns on the go. It can make decisions and explore effectively without pre-existing knowledge of a space.
-
Transparent, Flexible Navigation: Our model’s navigation behavior is based on a framework that uses Active Inference, making it adaptable and the behaviour becomes fully understandable by going through the equations. No black boxes.
-
Seamless Adaptation to Change: The model can handle changing environments, like the shifting layouts of a maze. This flexibility could make it useful for real-world applications where conditions vary.
What are its limits?
As interesting as this approach is, it as limitations to consider:
-
Expecting Priors: while it doesn’t need to be trained in a new environment, it still requires prior on what is considered an obstacle or not. It can be as simple as an obstacle detection (e.g. a lidar), or more complex such as recognising doors. Same with goals reachings, it needs to have knowledge of what its preference is if it want to aim for it.
-
Choices of directions: This current work expects the agent to move in cardinal directions only, in an open world, the options should be wider.
-
Gain in Modulability : this work is about efficient decision making to navigate and remember a new environment. To work in the real world, it requires to be integrated in a model able to parse sensor informations and reach objectives without hitting obstacles.
Why Is Remembering Potential Paths Important?
The real plus value of this work happens when the agent combines what it knows with what it predicts. By expanding its internal map over expected new rooms, it doesn’t just rely on what it sees in front of it and doesn’t forget doors it chose not to take. It also makes educated guesses about what might be in an unexplored areas. This ability to predict and adapt allows the agent to explore environments and reach objectives more efficiently, learning about new areas faster and making better decisions along the way.
Conclusion
Just like how you create a mental map of your surroundings as you explore new places, our agent uses predictions and actual observations to build its own map. When it predicts or sees something new, it updates its memory to include that information. By predicting what lies ahead and adapting to surprises (closed door, new room layout, kidnapping and relocation), it navigates environments in an efficient way, always learning and improving as it goes.