Adapting Artificial neural networks to data changes
Neural networks need to adapt to data changes
Artificial neural networks, trained on certain data, learns to interpret data that is similar to the ones for which it has been trained.
But what if the new data changes?
For example, a neural network trained to classify images under similar lighting conditions will struggle to classify those under darker conditions.
These domain shifts are worth attention, especially in real-world applications, when a neural network runs on an edge device and analyzes data sampled from a sensor.
In the domain of image sensors, for example, they can span from scene light changes to camera movement and noise induced by sensor aging.
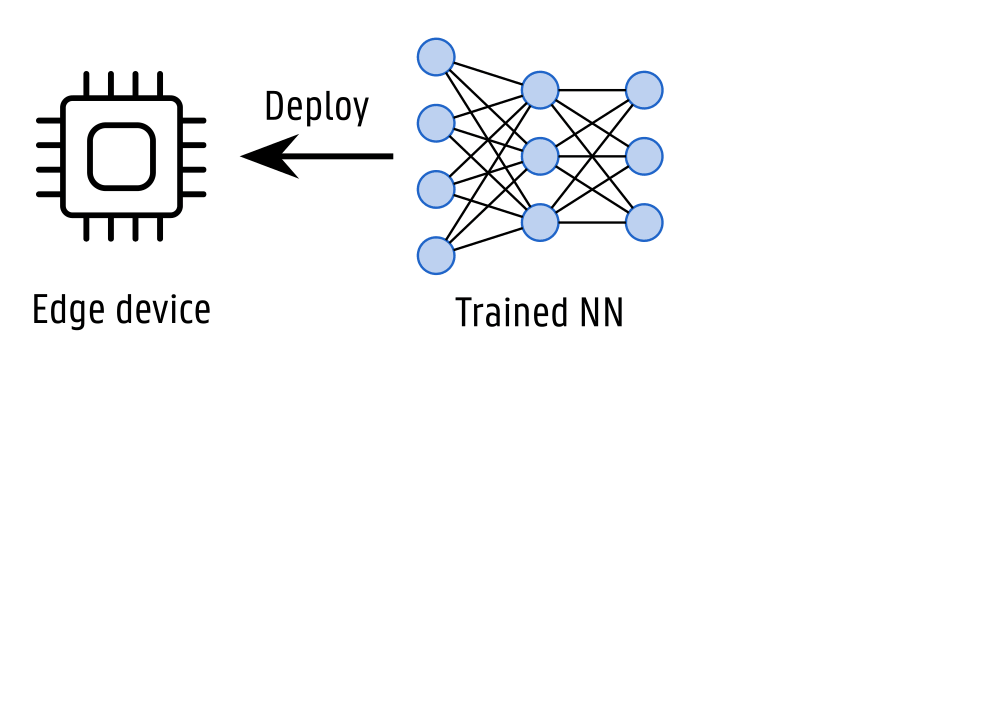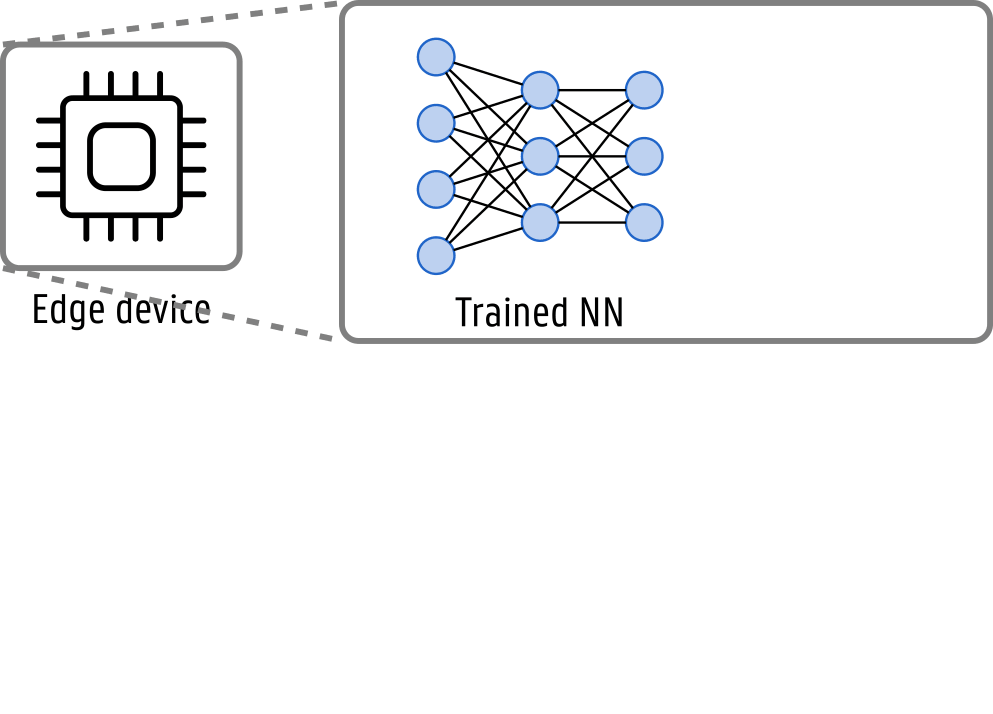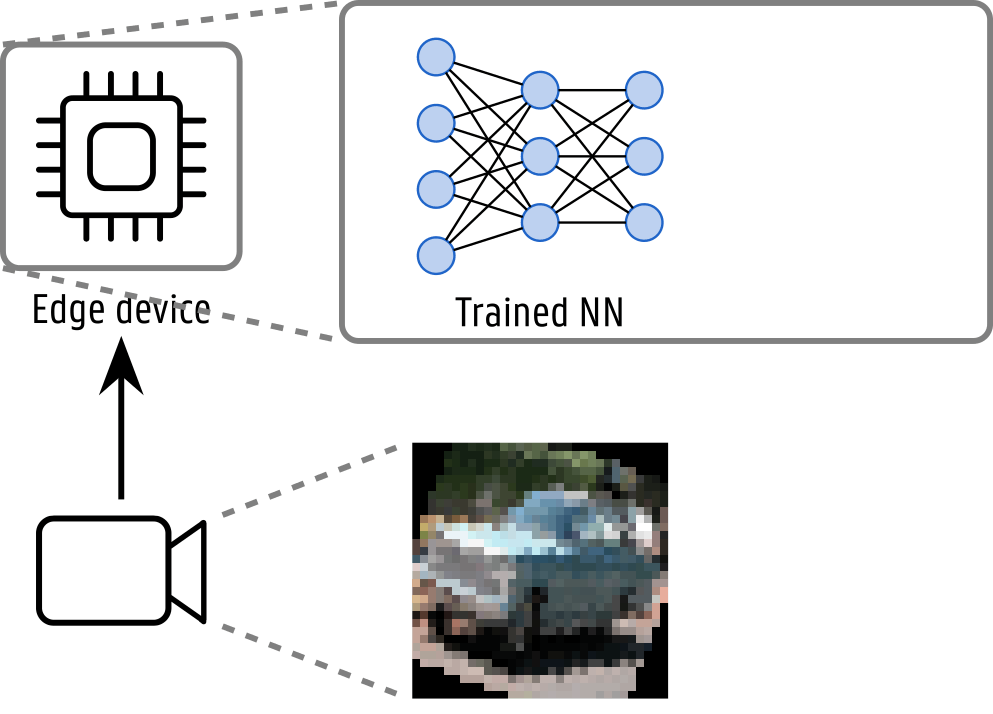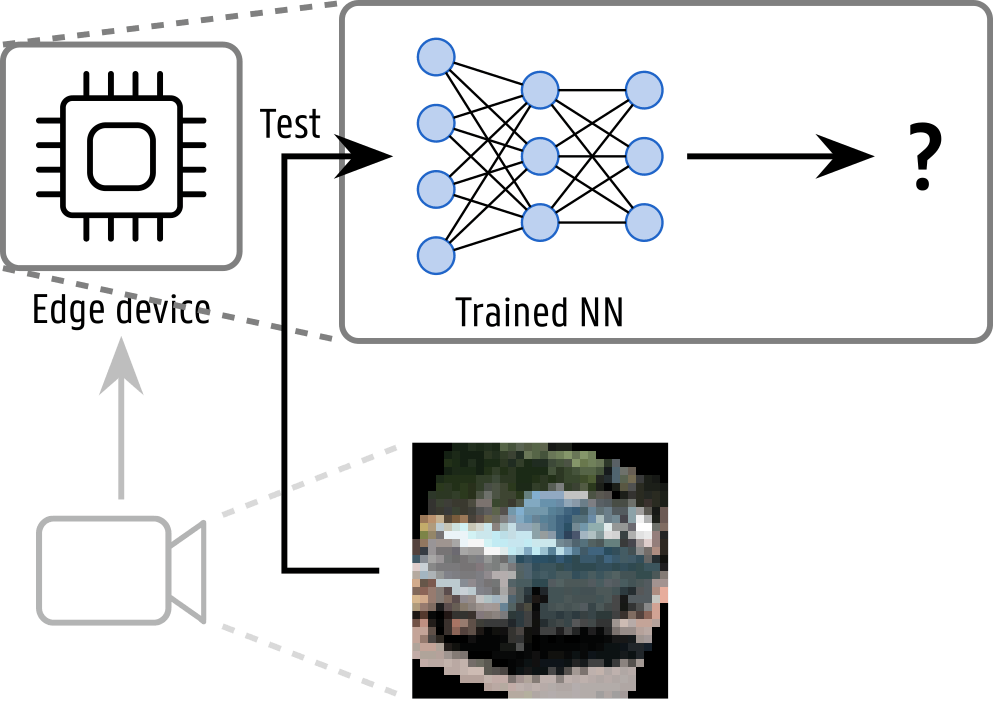
There is a need, therefore, to tackle domain shift to adapt a neural network to the new domains, every time the need arises.
Predictive Coding as a computationally efficient adaptation strategy
Performing the adaptation on-device is favorable in terms of privacy, communication overhead, and system cost. That is why we adopted a computationally efficient strategy that combines the robust representation learning of Backpropagation and the efficiency of Predictive Coding.
The Backpropagation algorithm is currently the predominant approach for training deep neural network architectures. It is, however, not without its limitations. BP requires the computation and transmission of global error signals, which can be computationally intensive.
Unlike Backpropagation, Predictive Coding relies on local computations and error-driven updates that align well with the distributed, event-driven nature of neuromorphic architectures. This makes it a compelling candidate for developing scalable, low-power learning algorithms suitable for real-time applications on energy-constrained edge devices.
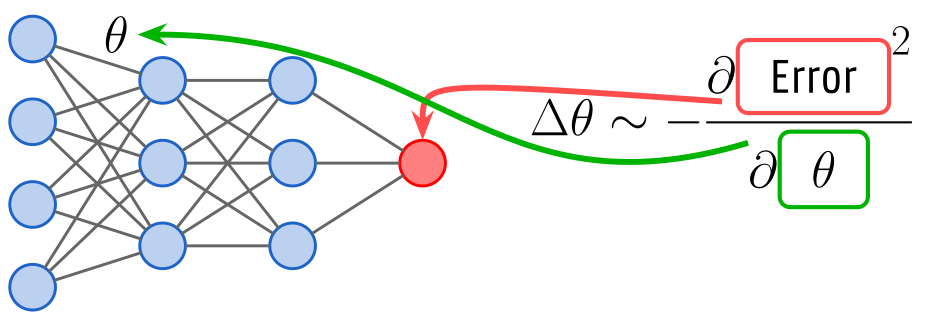
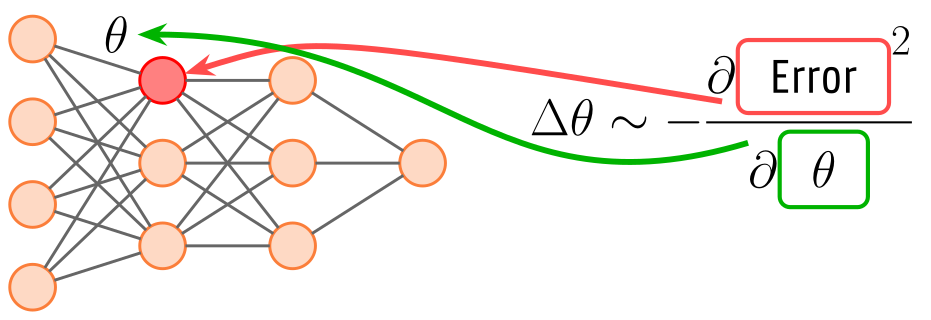
Despite the progress made in recent years, models trained using Predictive Coding still fall short of the accuracy levels achieved by those trained with Backpropagation.
That is why we propose a novel hybrid approach that combines the strengths of both algorithms.
Combining the strengths of Backpropagation and Predictive Coding
To design a solution that leverages the strengths of both Backpropagation and Predictive Coding, we introduce a two-stage training and deployment pipeline.
In the first stage, a model is trained offline using Backpropagation on high-performance cloud infrastructure, with virtually unlimited computational resources. This allows us to reach an accuracy level that would be currently impossible to achieve using Predictive Coding alone.
The trained model is then deployed on a resource-constrained edge device such as a wearable or sensor node. Over time, shifts in the input data distribution due to sensor drift, environmental changes, or user behavior may degrade model performance, necessitating continual adaptation. Predictive Coding is, therefore, used to adapt the model to these domain shifts, starting from the features trained with Backpropagation.
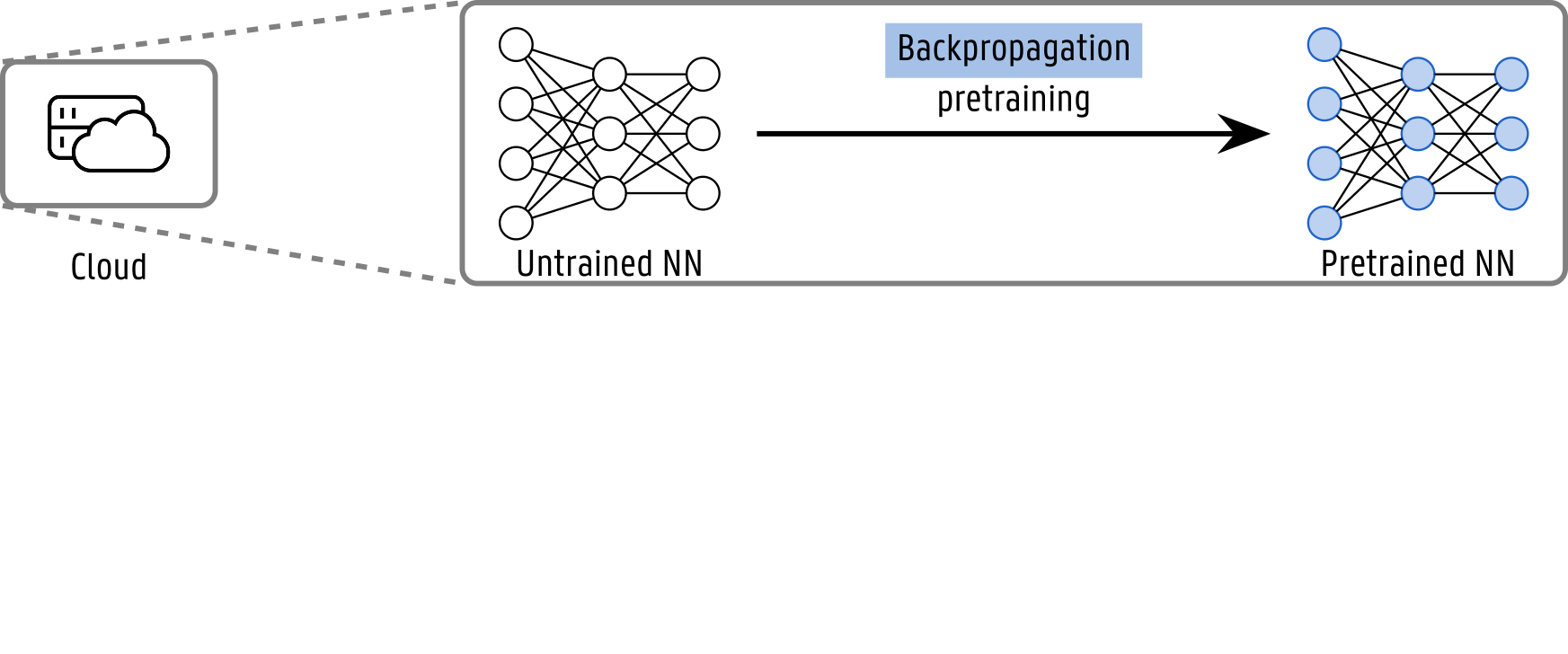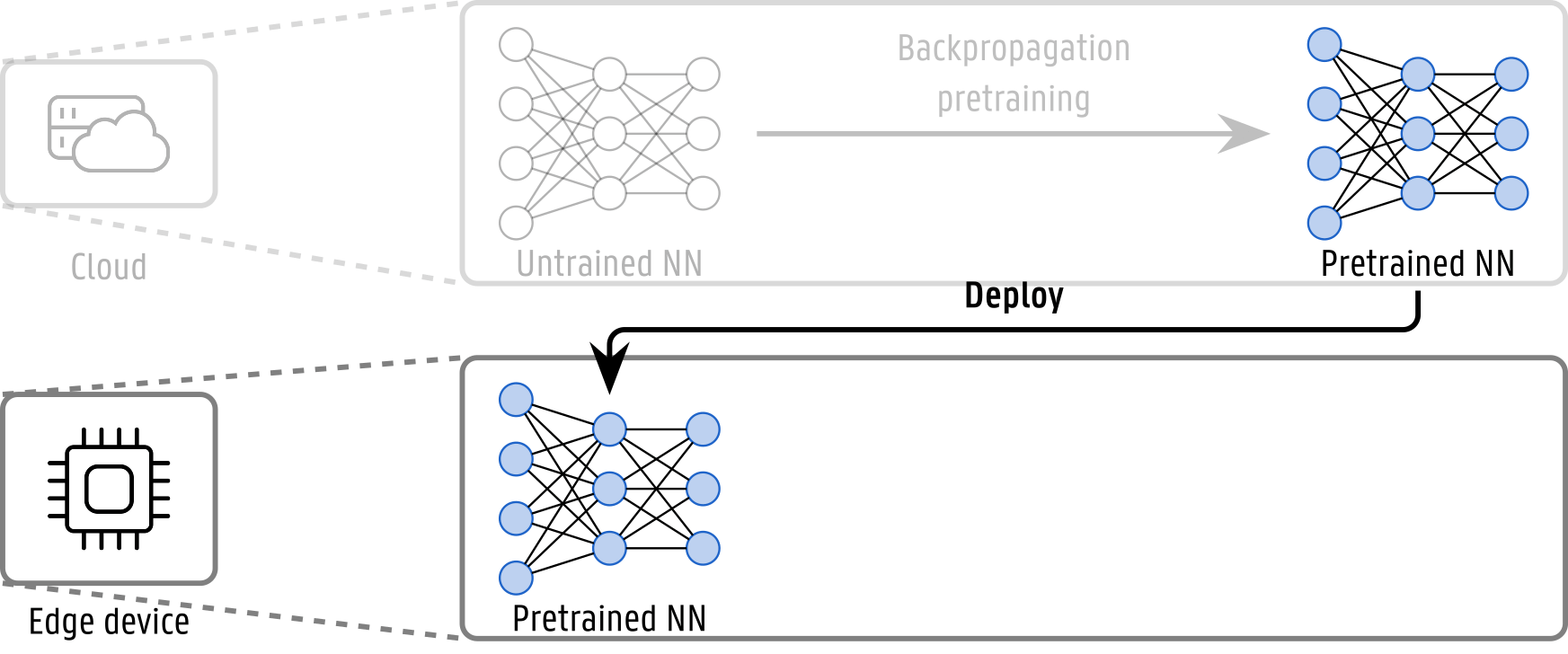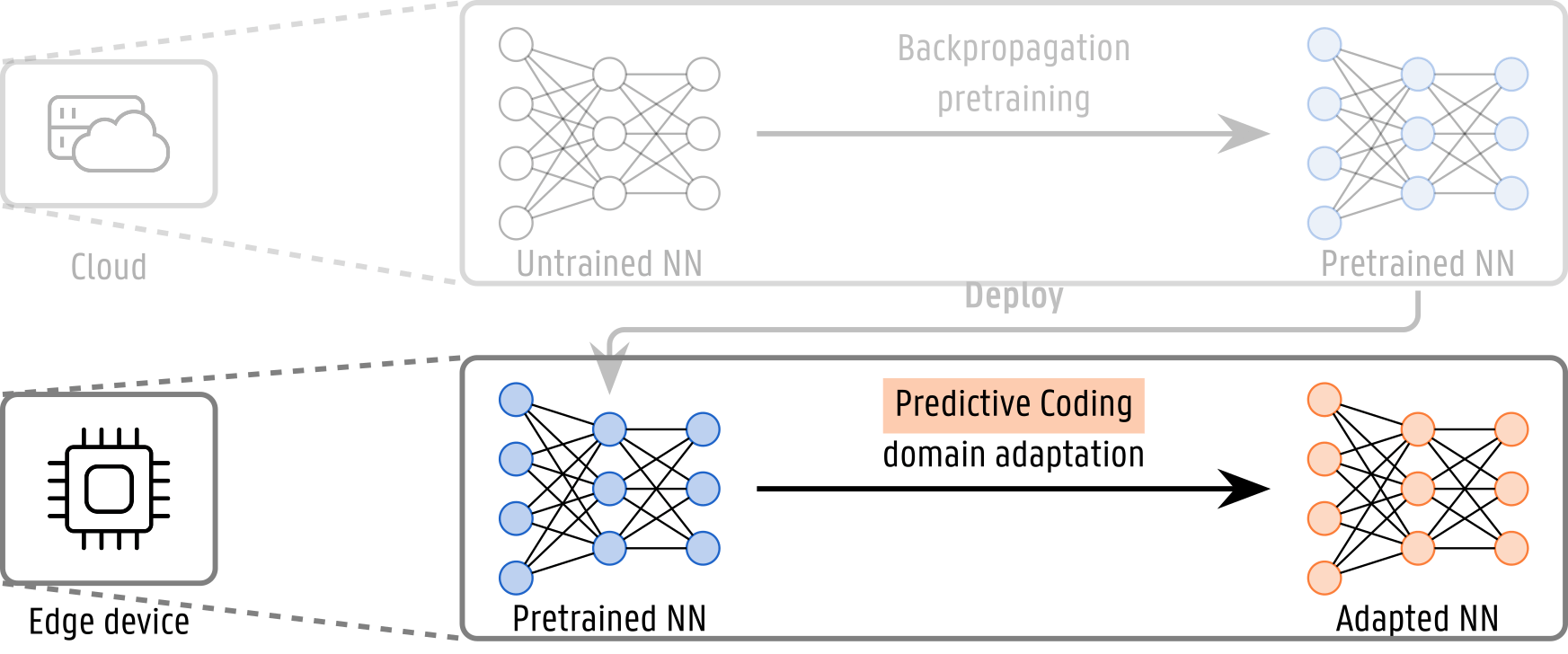
Testing the solution
One of the experiments we performed implies the supervised pretraining of a 5 layers Convolutional Neural Network to classify images from the Cifar-10 dataset, training the model on the entire dataset.
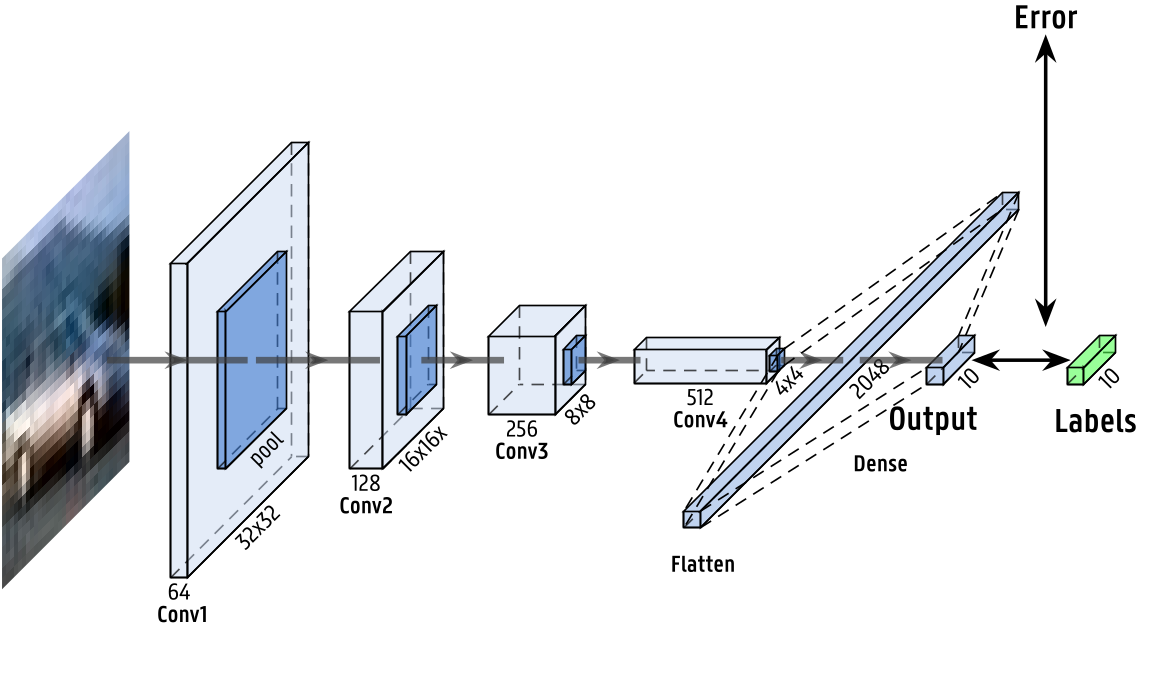
To simulate a domain shift, a rotation of 20 degrees has been applied to the whole dataset. In a real world scenario, this would correspond to a rotation of the image sensor angle.
The pretrained model has been domain-adapted with supervised training on the entire domain-shifted dataset, using Predictive Coding.
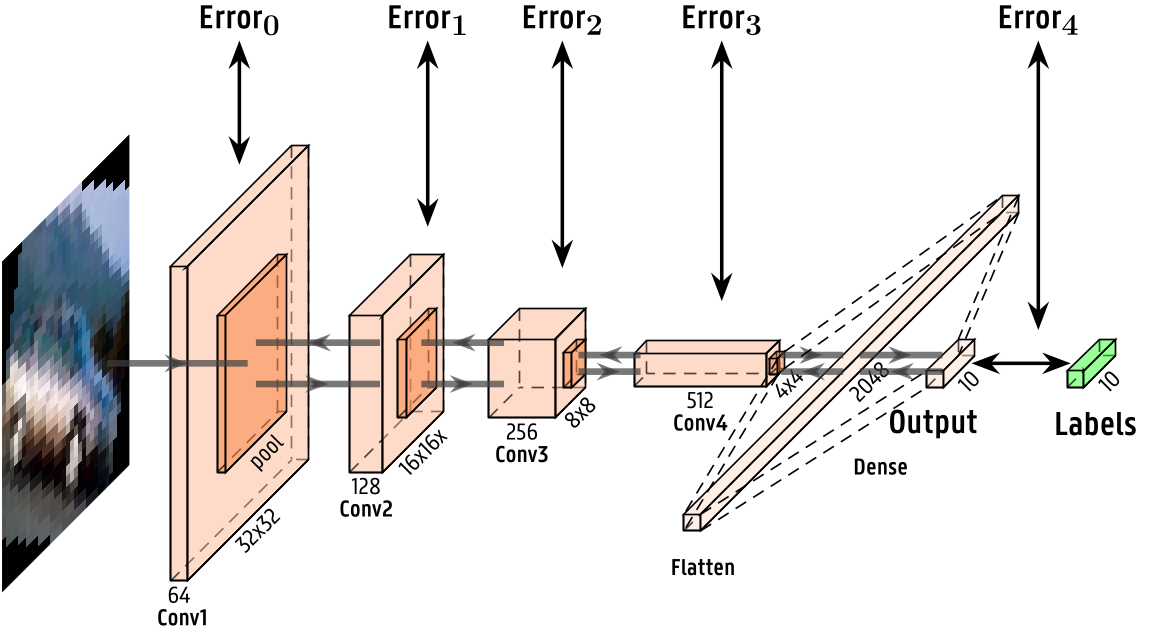
The Predictive Coding-based domain adaptation has been performed on GPU, together with the Backpropagation-based one as a comparison.
The results show that a combination of Predictive Coding (PC) and Backpropagation (BP) is, in fact, beneficial.
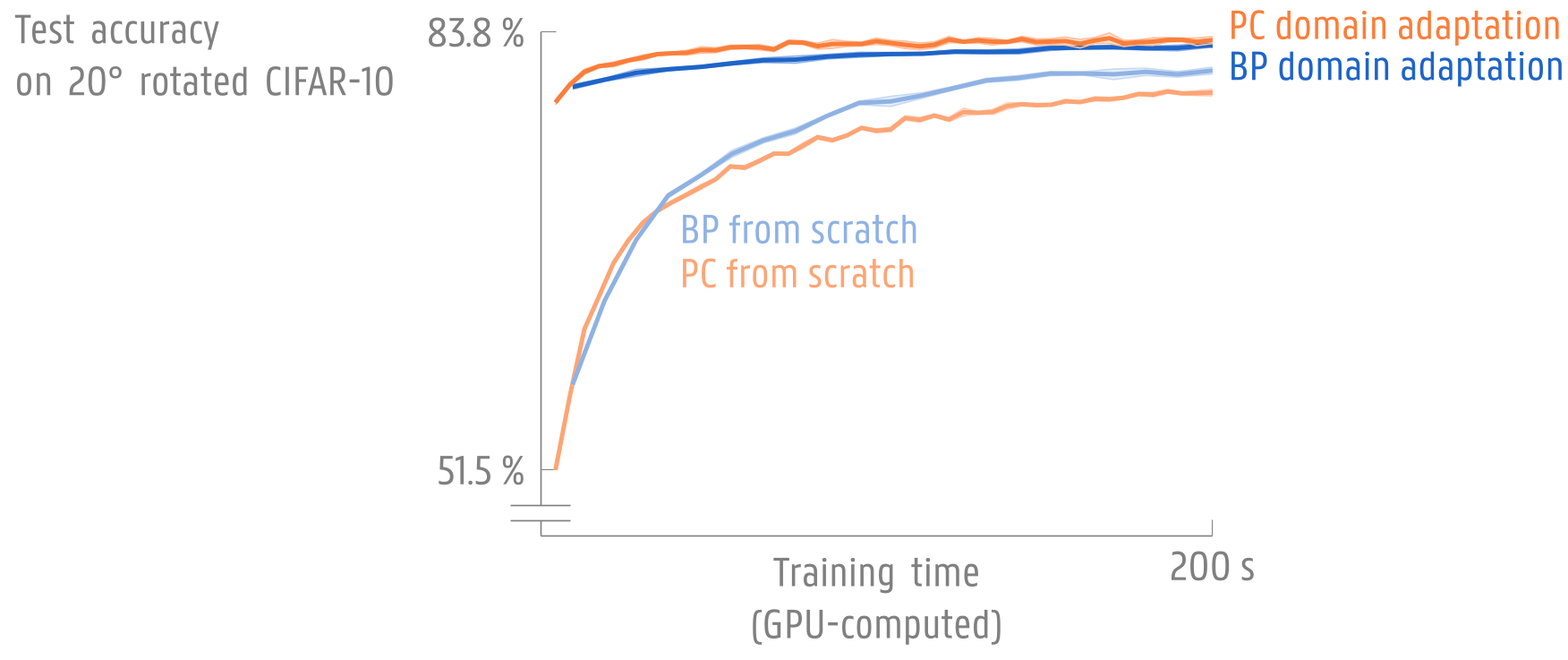
As Predictive Coding delivers faster training throughput while relying on features pretrained with Backpropagation, the Predictive Coding-based domain adaptation delivers a higher accuracy in time than the Backpropagation-based domain adaptation.
As a means of comparison, also the trainings from scratch have been performed on the same GPU, using the two training techniques. As expected, the results display an opposite behavior. In fact, the Backpropagation accurate representation learning outperforms the efficiency of Predictive Coding, even if training more slowly. This is why the Predictive Coding-based domain adaptation leverages the strengths of the two training techniques.
What’s next
As our technique proved to be useful in terms of computational efficiency, the next steps will imply its implementation on resource-constraned edge devices, and also neuromorphic hardware.
While the domain adaptation procedure was completely supervised in this work, this might not be feasible in real-world environments. More research into unsupervised or self-supervised approaches in combination with Predictive Coding is, therefore, a highly interesting research direction.
Find the integral version of our research in our paper: https://arxiv.org/abs/2509.20269.