Ising machines for robot control
A fully autonomous robot is, at its core, a real-time computing system. It continuously runs a rich stack of workloads: learning and updating world models from sensory data, performing perception and localization, planning and executing actions, and coordinating with other agents. Today, most of these submodules run on an embedded CPU or GPU on the robot itself, or are offloaded to the cloud.
Unconventional compute platforms are hardware that exploits physical phenoma or non-Von Neumann architectures to solve certain problem classes more efficiently. Neuromorphic chips, analog in-memory compute accelerators, and Ising machines each have their own native computational primitive. At DECIDE, we are exploring which of the robotic workloads can be mapped onto unconventional hardware, and what efficiency gains can be reached.
In this post, we zoom in on one particularly compute-hungry workload: trajectory optimization for real-time robot control. Specifically, we look at Model Predictive Path Integral (MPPI) control, which samples thousands of candidate trajectories from a dynamics model at every timestep and scores them against a cost function. We show how MPPI can be reformulated as an Ising optimization problem, suited for running natively on probabilistic co-processors.
Ising Machines and probabilistic computing
At the heart of an Ising machine is a deceptively simple idea. Given a vector of binary variables and a matrix encoding the interactions between them, the goal is to find the assignment that minimizes:
This problem class is known as QUBO (Quadratic Unconstrained Binary Optimization), and it is equivalent to finding the ground state of an Ising Hamiltonian. An Ising Machines solves it not by explicit search, but by letting physical dynamics do the work.
The key building block is the probabilistic bit, or p-bit: a stochastic unit that fluctuates between 0 and 1, with its switching behavior governed by the influence of its neighbors. The result of this collective dynamics between the coupled p-bits is that the Ising machine samples configurations according to the Boltzmann distribution:
where is an effective temperature controlling the sharpness of the distribution. At low temperatures the network concentrates on the ground state; at higher temperatures it explores more broadly. This means an Ising machine is not merely an optimizer but a sampler. What makes this practically appealing is that p-bits can be implemented in several ways that are also suitable for edge deployment, ranging from standard CMOS circuits to magnetic tunnel junctions.
Model Predictive Path Integral
Model Predictive Control (MPC) computes an optimal control sequence by solving a finite-horizon optimization problem at each timestep, relying on a model of the system dynamics to predict future states. This repeated optimization can be computationally demanding, particularly under strict latency or energy constraints. Model Predictive Path Integral (MPPI) control offers a probabilistic perspective on this problem.
Rather than solving a deterministic optimization directly, MPPI samples control trajectories perturbed by Gaussian noise and assigns each trajectory a weight according to the exponential of its negative cost:
where is the trajectory cost and is a temperature parameter regulating exploration. Low-cost trajectories are exponentially more likely, analogous to a Boltzmann distribution in statistical mechanics.
The optimal control is then recovered as the weighted average over all sampled trajectories. Convergence to a good solution therefore relies on drawing a large number of samples to adequately cover the space of possible trajectories. The speed at which those samples can be generated is the primary bottleneck for real-time performance.
Mapping MPPI onto an Ising machine
The key insight is that the Boltzmann distribution underlying MPPI and the equilibrium distribution of an Ising machine are the same mathematical object. The challenge is bridging the gap between the continuous action space of MPPI and the binary variables of an Ising machine. This is achieved in two steps.
First, continuous control inputs are discretized using a binary expansion matrix , such that the control sequence where is a binary vector.
Second, the MPC cost function is linearized around a nominal trajectory and rewritten as a quadratic function of , yielding a QUBO of the form:
where and encode the trajectory cost.
The Boltzmann distribution over this energy function is then exactly the MPPI sampling distribution in the binary action space. Rather than drawing Gaussian samples on a CPU, an Ising machine can now generate samples from this distribution natively via Gibbs sampling, with the final control action recovered by averaging samples and rounding.
Results
We tested Ising-MPPI on a kinematic bicycle model, tracking a set of randomly generated reference trajectories. The animation below visualizes the sampling procedure.
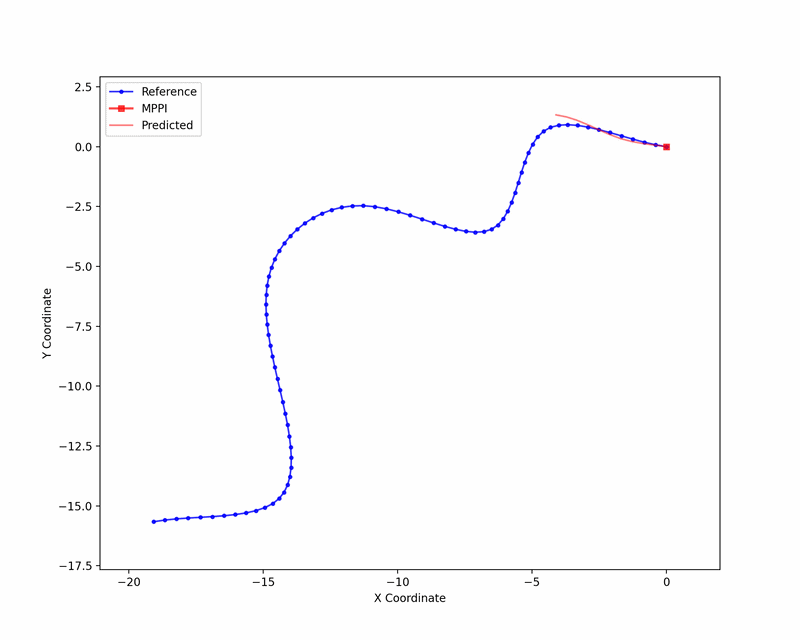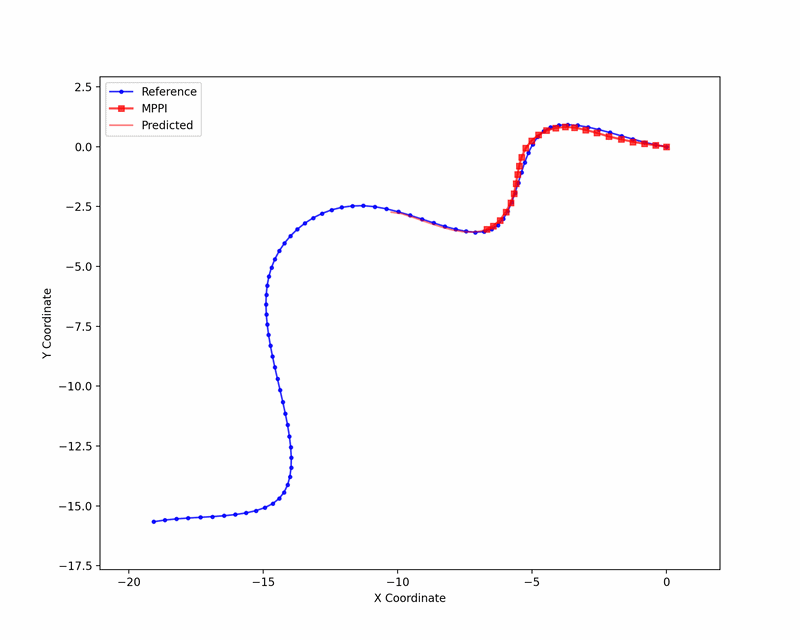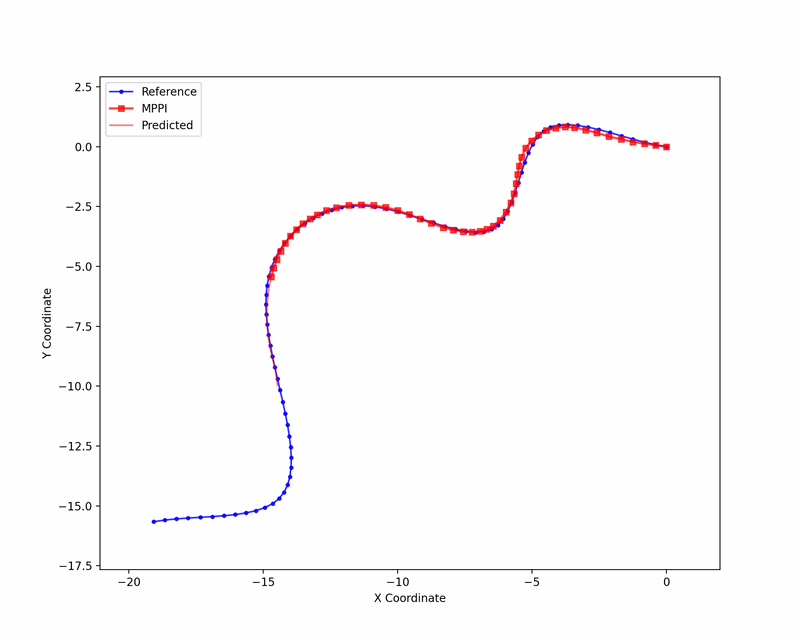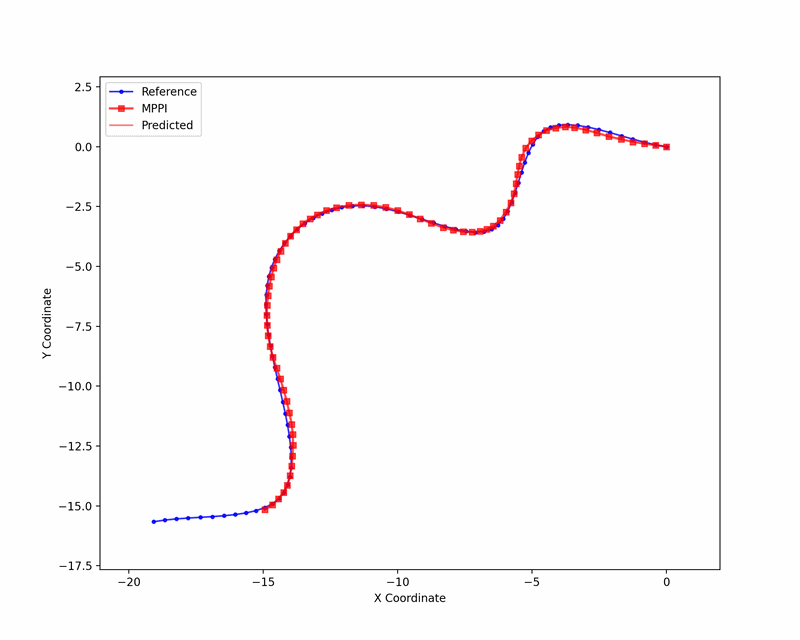
The approach achieves comparable tracking performance to a linearized MPPI baseline without Ising hardware, with the remaining gap to a reference MPPI implementation on the full nonlinear model attributable to linearization and binary discretization. Importantly, Ising-MPPI converges to low tracking error with fewer samples than the linear baseline. This is a promising sign for hardware deployment where sampling throughput is the primary resource.
Future work
The most immediate limitation of the current approach is its reliance on linearized dynamics. A natural extension is to replace the linear model with a learned world model, encoding the system dynamics in a neural or energy-based model trained from data. This would remove the linearization assumption and allow Ising-MPPI to operate in more complex, nonlinear environments.
A second direction is online learning and adaptation. In real deployments, a robot’s world model will inevitably be imperfect, and the ability to update it continuously as new observations arrive is essential. Ising hardware is well suited to this setting: because the QUBO formulation is rebuilt at each control step from the current model and state, incorporating an updated model requires no architectural changes.
Beyond control, we are exploring which other workloads in the robot compute stack are amenable to similar mappings. Localization, planning under uncertainty, and multi-agent coordination all involve inference or optimization. You can find the full manuscript here.