Robot Autonomous Navigation
Teaching Robots to Find Their Way Like Humans Do
Imagine you’re exploring a new city. You don’t have a map, but as you wander, you piece together a mental picture of the streets, landmarks, and shortcuts. You might get lost, but you recover by recognising a familiar café or a square you passed earlier. This ability to build and update an internal “cognitive map” is what makes humans such remarkable navigators.
Now imagine teaching a robot to do the same.
Most robots today still rely on carefully prepared maps, GPS, or hours of pre-training to move around. Take away the map or change the environment, a door moves, furniture shifts, cars park in new spots and see how many systems struggle. For robots to be truly autonomous, they need to handle unfamiliar spaces the way people do: exploring, learning, and adapting on the fly.
A biologically inspired solution
Our research takes inspiration directly from neuroscience, particularly how the hippocampus helps animals and humans navigate. We designed a robot navigation framework based on a theory called active inference. In simple terms, Active Inference is about constantly predicting what should happen next, comparing it to what actually happens, and adjusting when things don’t match up.
Instead of relying on fixed maps, our robot builds its own cognitive map as it moves. This map is a network of experiences:
-
Places it could reach.
-
What it could see (a 360° panorama stitched from its cameras).
-
How it can move between locations.
Like a human traveller, the robot can use this internal map both to localise itself (where am I?) and to plan ahead (where should I go and how?).
At each location, we take pictures of the surrouding and forma panorama of it. That is our observation. We also consider the perceived motion between the previous and current pose and infer our approximate position given that information. With those two elements, we can determine where we are, our state, our location.

What makes this different?
-
Self-learning: The robot teaches itself as it explores, without needing pre-training.
-
Robustness: If its wheels slip or its odometry drifts, it doesn’t get lost, it corrects itself by recognising familiar sights.
-
Flexibility: It can use any sensors (cameras, depth sensors, even Lidar) as long as they help distinguish places.
-
Exploration vs. goals: Like a curious human, the robot balances between discovering new places and reaching set destinations.
This system is largely based on the model presented in Navigating and Learning in an unknown environment
How do we navigate
While we previously verified our model in a 2D environment we are now verifying it in the real world. Which is much more challenging. Our map building has been improved to consider all directions around our robot. Moreover we do not construct policies at initialisation but construct them at each new step considering the situation. For that, we use a Monte Carlo Tree Search (MCTS) combined with Active Inference exploration and exploitation term. When predicting the future consequences of actions, we call it the Expected Free Energy.
Exploration: How to maximise environment understanding
Exploitation: What it prefers observing
In our case we have:
State information gain
Parameters information gain
Expected value vs desired value
over:
Observation
Position
State
This is great, but, what if we can’t predict far enough? What if there is nothing to explore around, if the place i want to reach (the kitchen) is too far from me to predict in a given set of steps?
It’s exactly for that problematic that we also inserted an induction term that propagates interesting states exploitation value over the horizon range of the imagination, by adding a weight to actions leading toward them. We have our map composed of many locations -or states- (circles) and we have a location we want to reach, a state (dark green circle). The interest value of the goal state propagate between adjacent locations all the way to our agent. Thus even if the goal is over the imagination range of the agent.
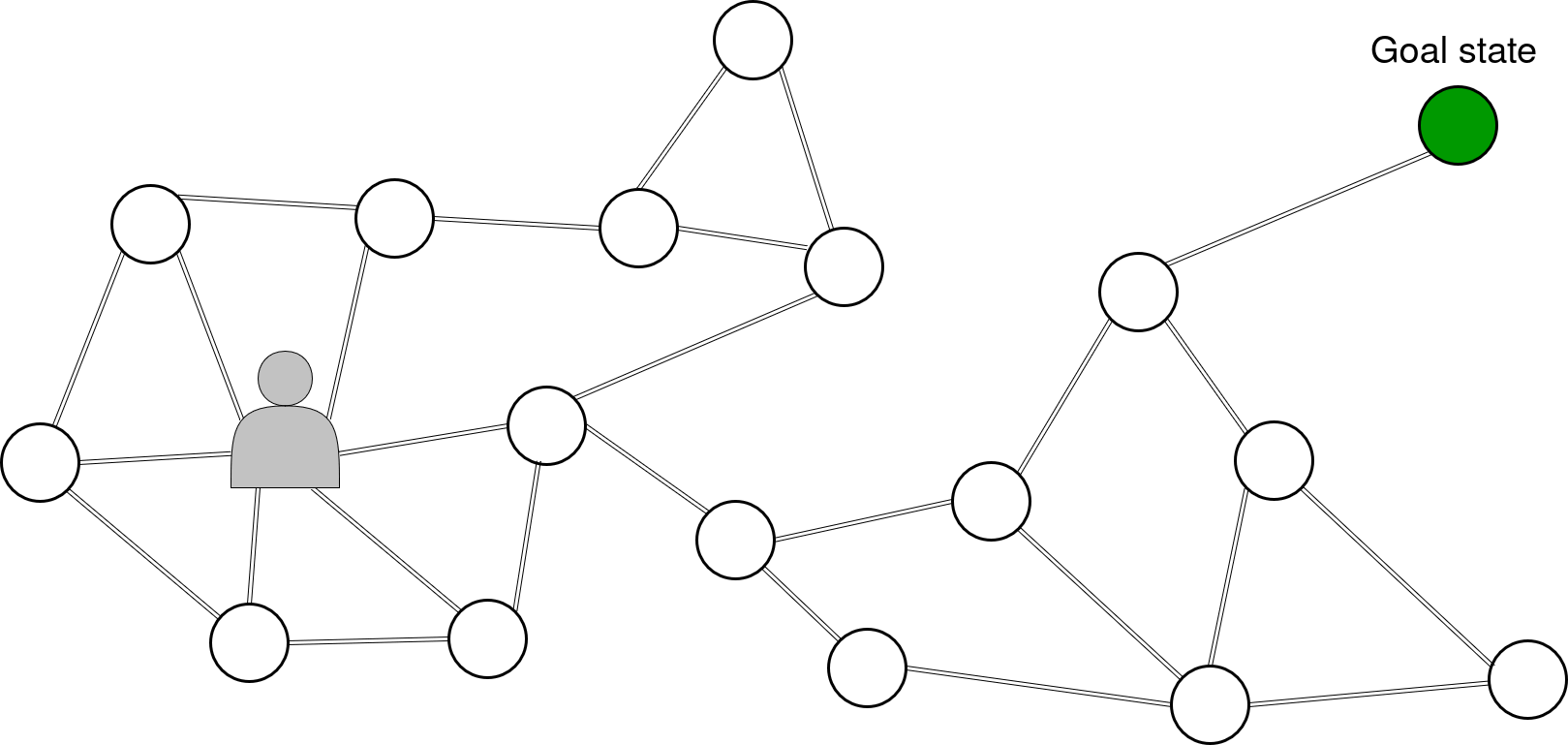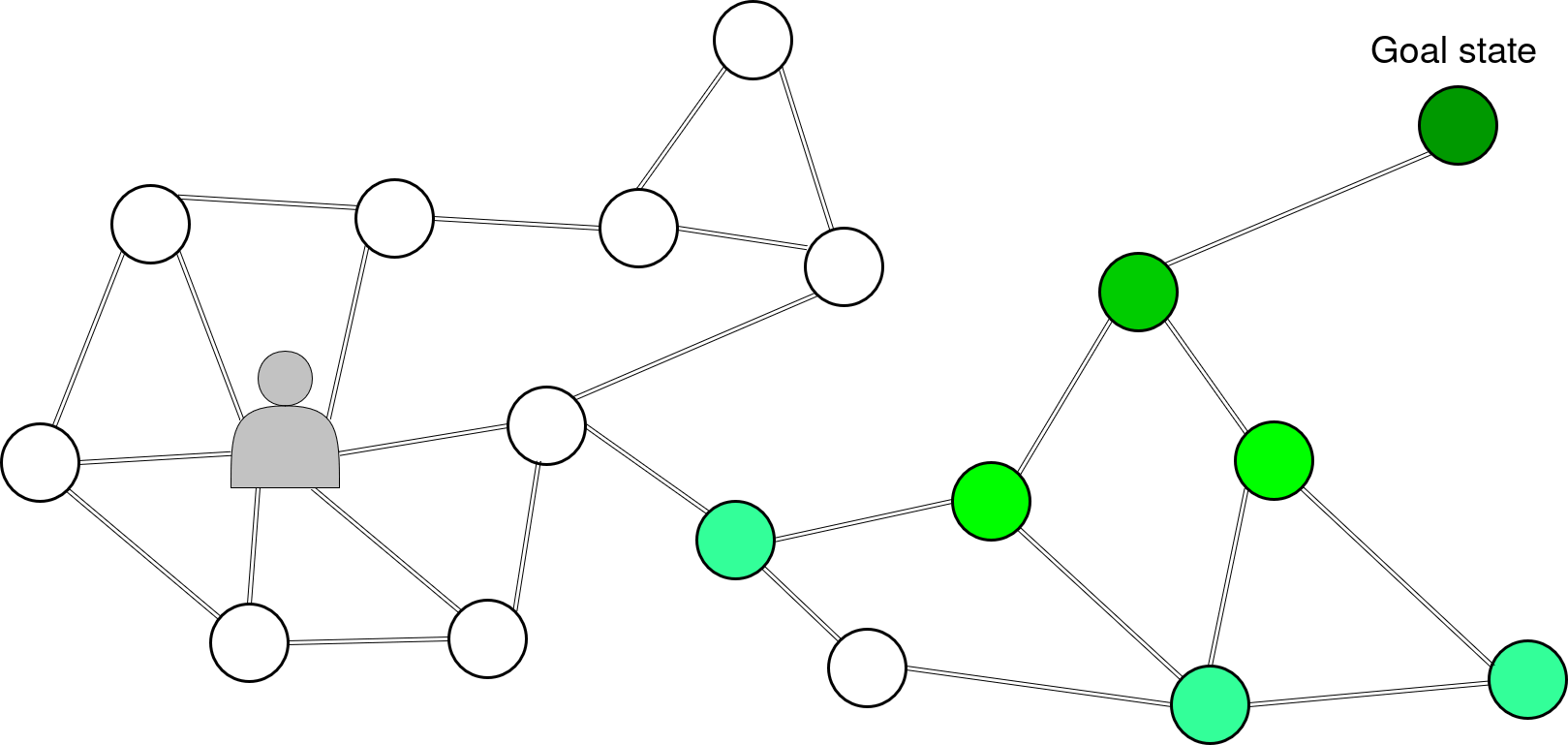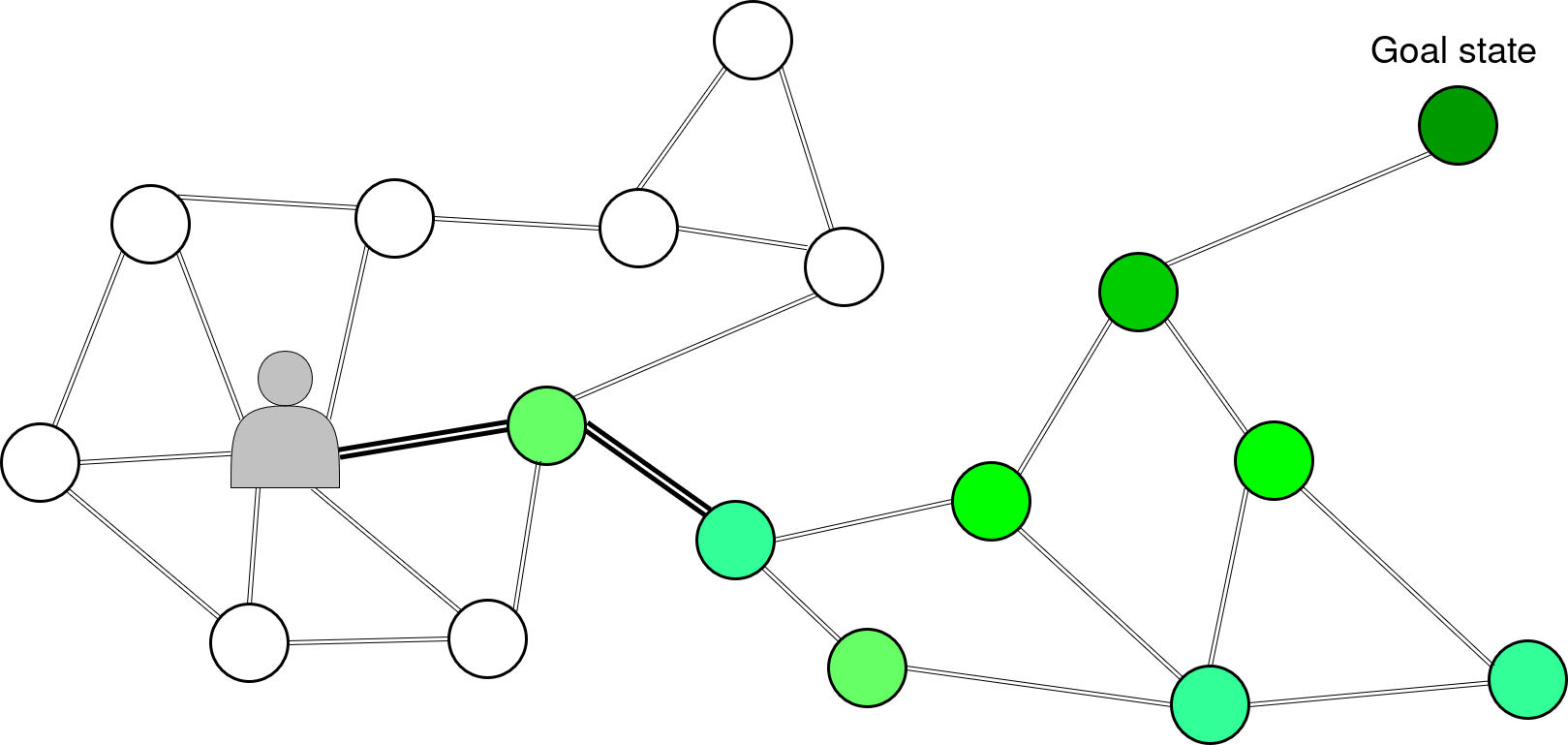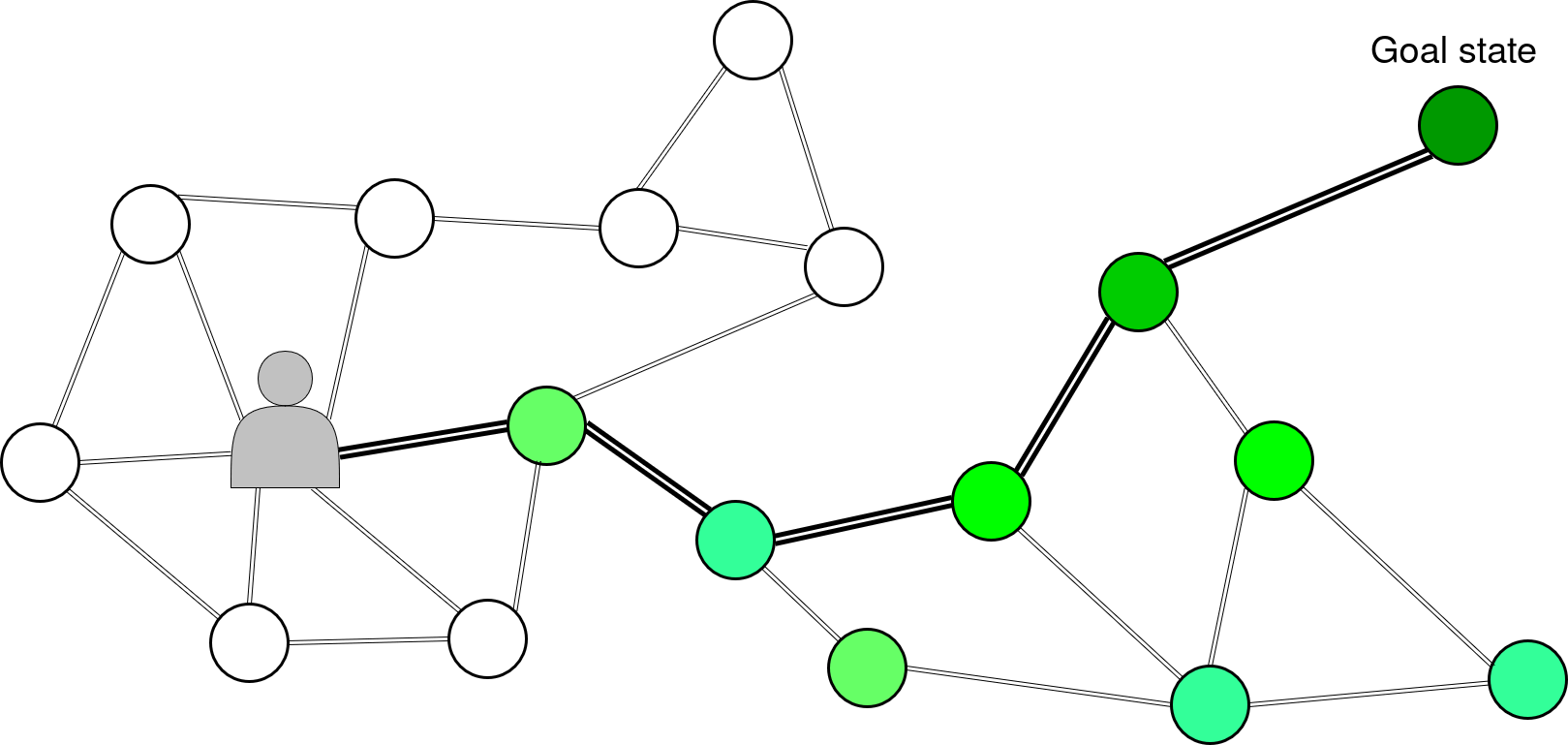
Navigation on display
We demonstrated that our model works, without tweaking, in many diverse situations from simulated houses to real world garage. Our largest environment to explore being a 325m^2 parking lot

Our model always reaching all goals given, as long as it was able to recognise them, else it would explore to maximise its information gain.
Goal Panorama

Taken path to reach it
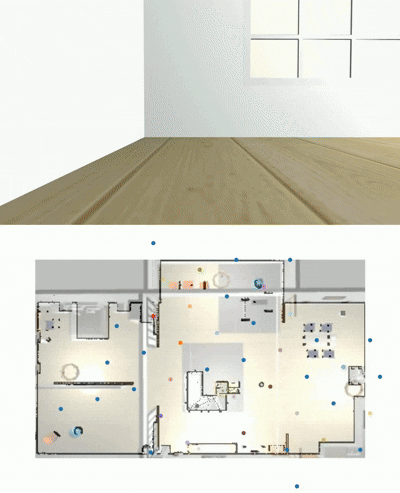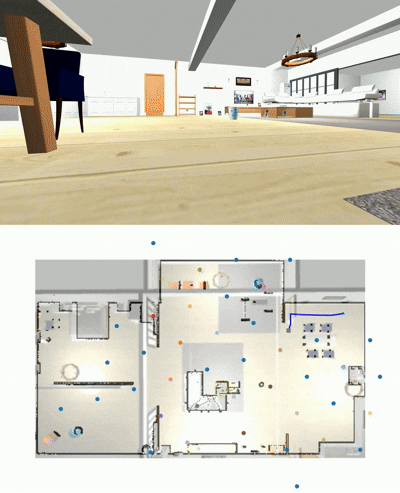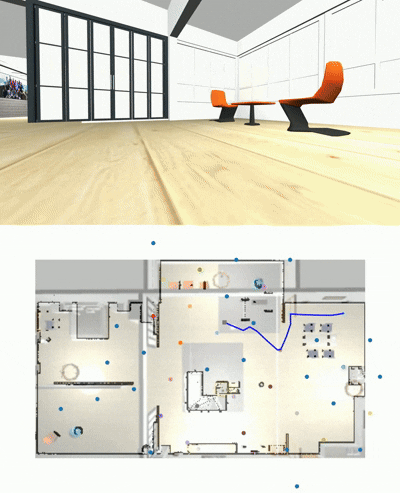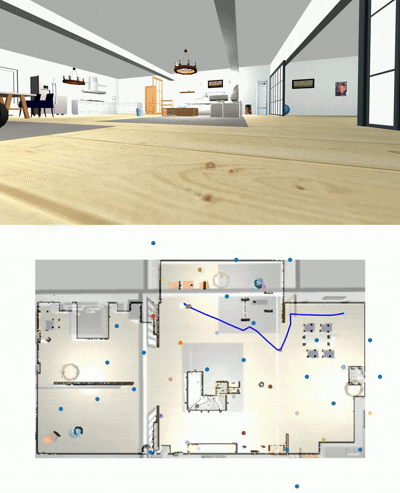
Wonderful, it takes decision to move around. But can it challenges existing navigation models?
We could compare it to purely exploration systems, as we found no model as modulable as us, able to explore and reach objectives, while not requiring training. We compared our exploration efficiency to the algorithmic models FAEL and GBplanner (an improved version of DARPA winner 2021) and an heuristic model (Frontiers).
Our Coverage Efficiency (covered distance in m^2 /traveled distance in m) was appreciated vs a human teleoperated exploration and our success rate (percentage of full succesful exploration over the total number of trials). The figure below presents the results, CE and Success Rate, respectively, over all environments.

We can see that we demonstrate a good balance between exploration efficiency and robustness, which we do not have to envy other more classical navigation models.
Why it matters
This work moves us a step closer to robots that can truly operate in the wild: homes, offices, factories, or disaster zones, without needing perfect maps or endless training data. By grounding robot navigation in the same principles that biology evolved in the brain, we open the door to machines that are not just programmed to move, but able to learn, adapt, and find their way.
Usage example in real world
Flanders Make used this model on a MIR robot with a 360’ camera and a forward camera. Panorama were taken by turning around and information about the image was extracted with Gemini, to use for goal oriented behaviour toward specific objects instead of panorama.
Limitations
So, can we use it in factories of the go? Well, not yet, there are still limitations
-
Our system sometimes “over-explores” open spaces and “under-explores” narrow but useful areas. Smarter ways to group space by information value could fix this.
-
We can move between location, but what if we want to stop right in between?
-
Planning happens at a single scale. Adding multi-scale reasoning would help the agent cover big areas faster without missing details.
-
The vision system is fairly basic. Adding semantic understanding (like recognising objects or landmarks) would make goal-finding more reliable.
-
As maps get bigger, older memories fade, which can force the agent to revisit places unnecessarily. We need more adaptive memory handling.
-
Extreme environment changes or sensor failures still cause issues. More robust sensing would make the system harder to break.
Sources
The full paper explaining this work can be found in Zero-shot Structure Learning and Planning for Autonomous Robot Navigation using Active Inference
The code is available at https://github.com/decide-ugent/aimapp